Python独学ならTech-Joho TOP > いろいろやってみた > PowerPointアドインを作って、スライドをセクションごとに保存してみた
やりたいこと
表記の通りですが、私はOffice2010あたりから追加されたパワーポイントのセクション機能を多用しています。
他にあまり使っている人を見たことがありませんが、コンテンツを文章の章のように分けたいときに便利です。
今回、セクションのあるパワーポイントのスライドの、各セクションを別ファイルとして保存する作業が必要になりました。
そこで、pptxファイルをセクションで分割保存する機能をアドインとして作りました。
マクロは比較的よく作りますが、アドインは初めてなので、その手順をメモして公開します。
言い訳しておきますが、あまり良い設計ではないかもしれません。
必要なツールのインストール
まず、開発の前に、Visual Studio 2017をインストールしました。
次に、プロジェクトを作るにあたって”Microsoft Office Developer Tools”をインストールします。
画面左上の ファイル > 新規作成 > プロジェクト
でウインドウが開くので、左下の 「Visual Studio インストーラーを開く」をクリックします。
開いた「Visual Studio インストーラー」の「製品」タブ内を下のほうにスクロールして「Office/SharePoint開発」を探し、チェックボックスにチェックを入れて、右下の「変更」を押してください。
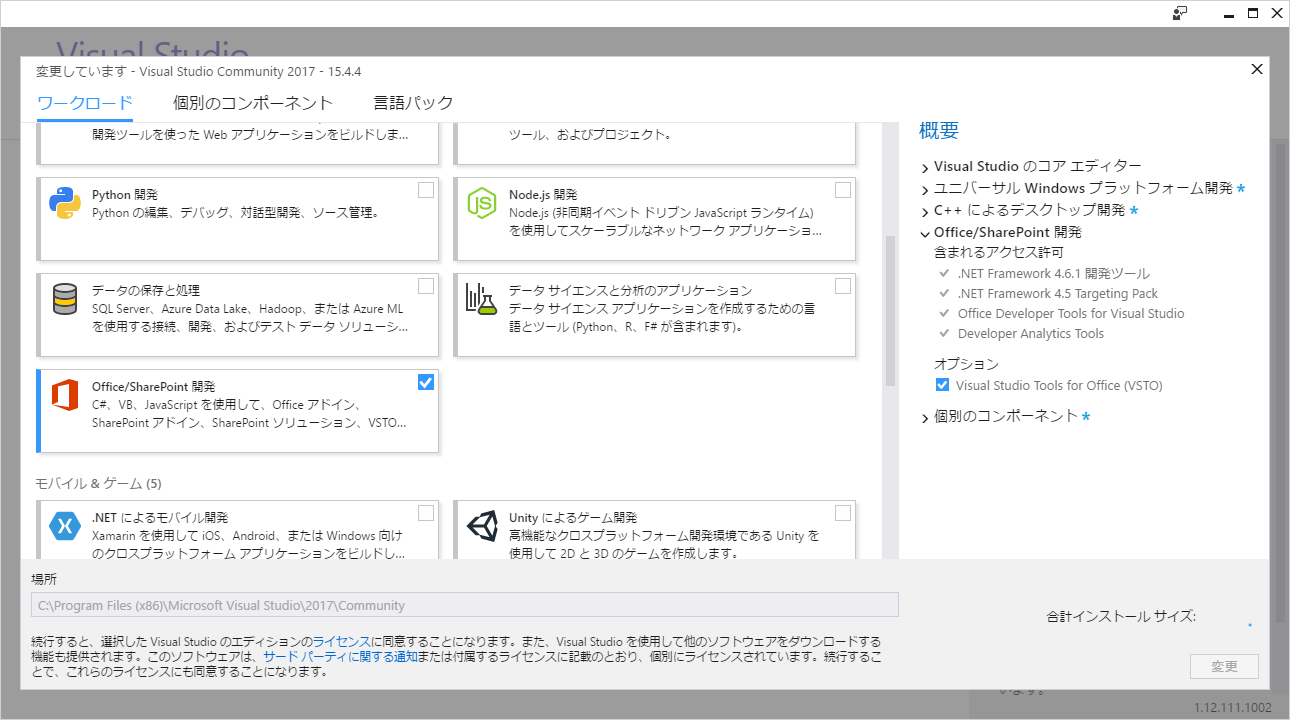
もしVisual Studioが開いていると、警告が表示されるので、Visual Studioを終了して「実行」を押してください。
インストールが始まります。
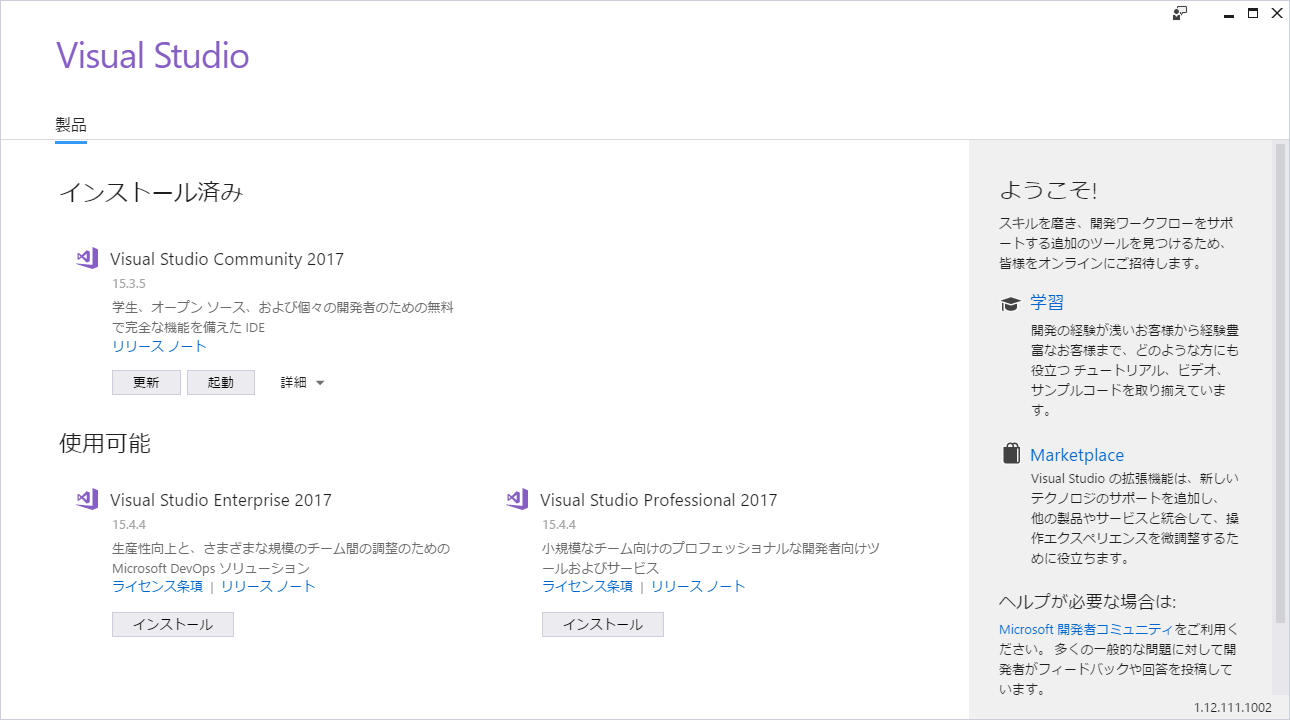
インストールが完了したら、「起動」を押してください。
1.プロジェクトを作る
プロジェクトを作ります。
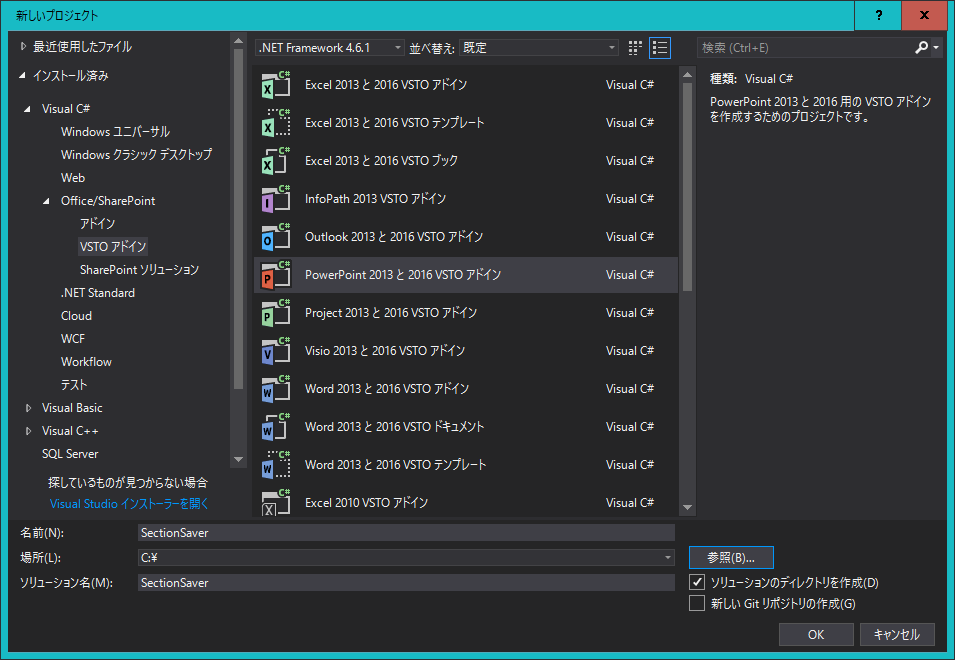
画面左上の ファイル > 新規作成 > プロジェクト > Office/SharePoint > VSTOアドイン > Powrpoint2013と2016 VTSOアドイン を選択し、名前や場所を適切に変更して、「OK」を押してください。私は「SectionSaver」という名前にしました。
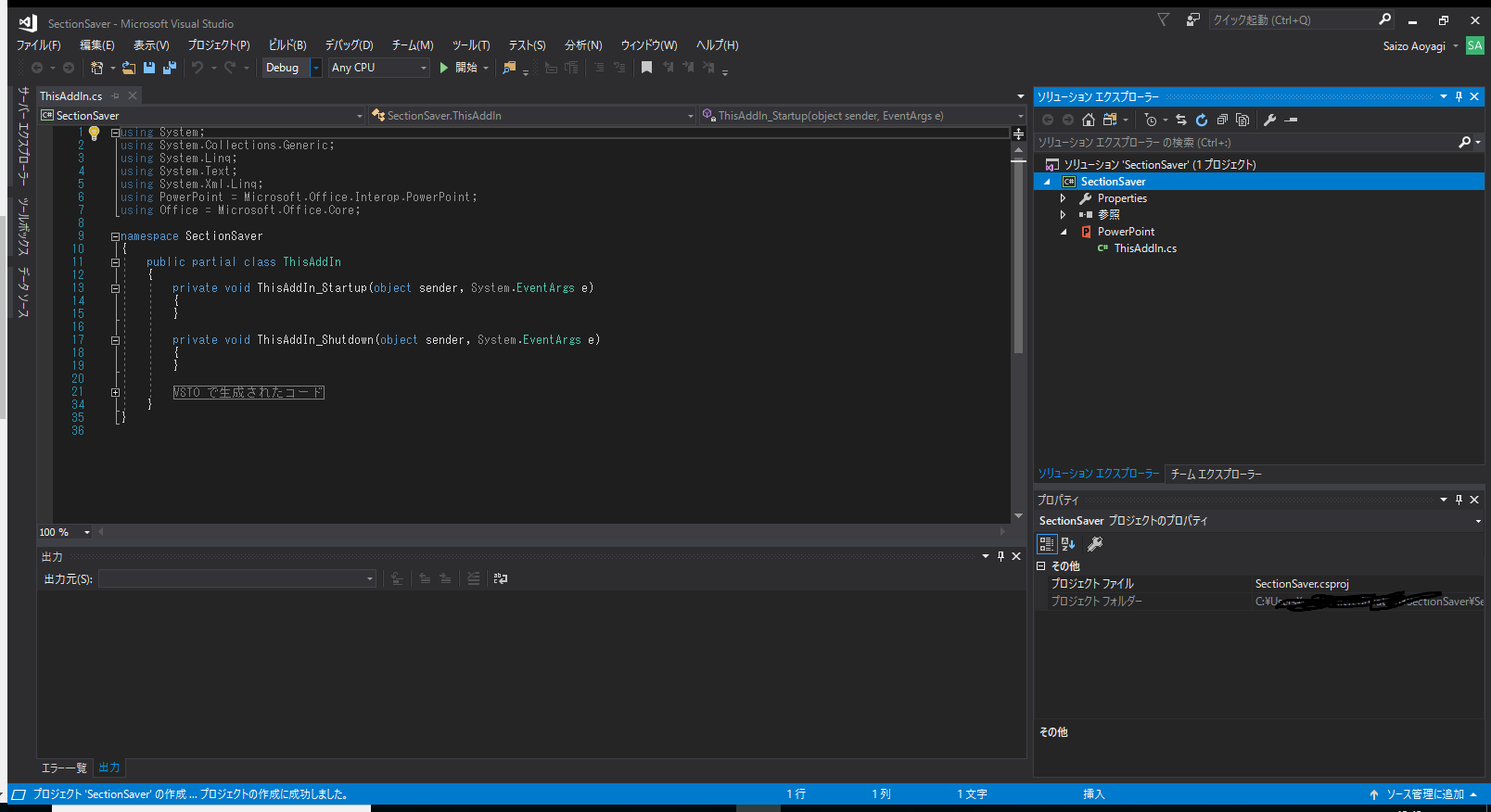
リボンにボタンを作る
まず、リボンデザイナーを使ってリボンを作ります。
画面上日のプロジェクト > 新しい項目の追加 をクリックし、開いたウインドウで、
リボン(ヴィジュアルなデザイナー)を選択して、名前は「Ribbon1.cs」にして、「追加」をクリックします。
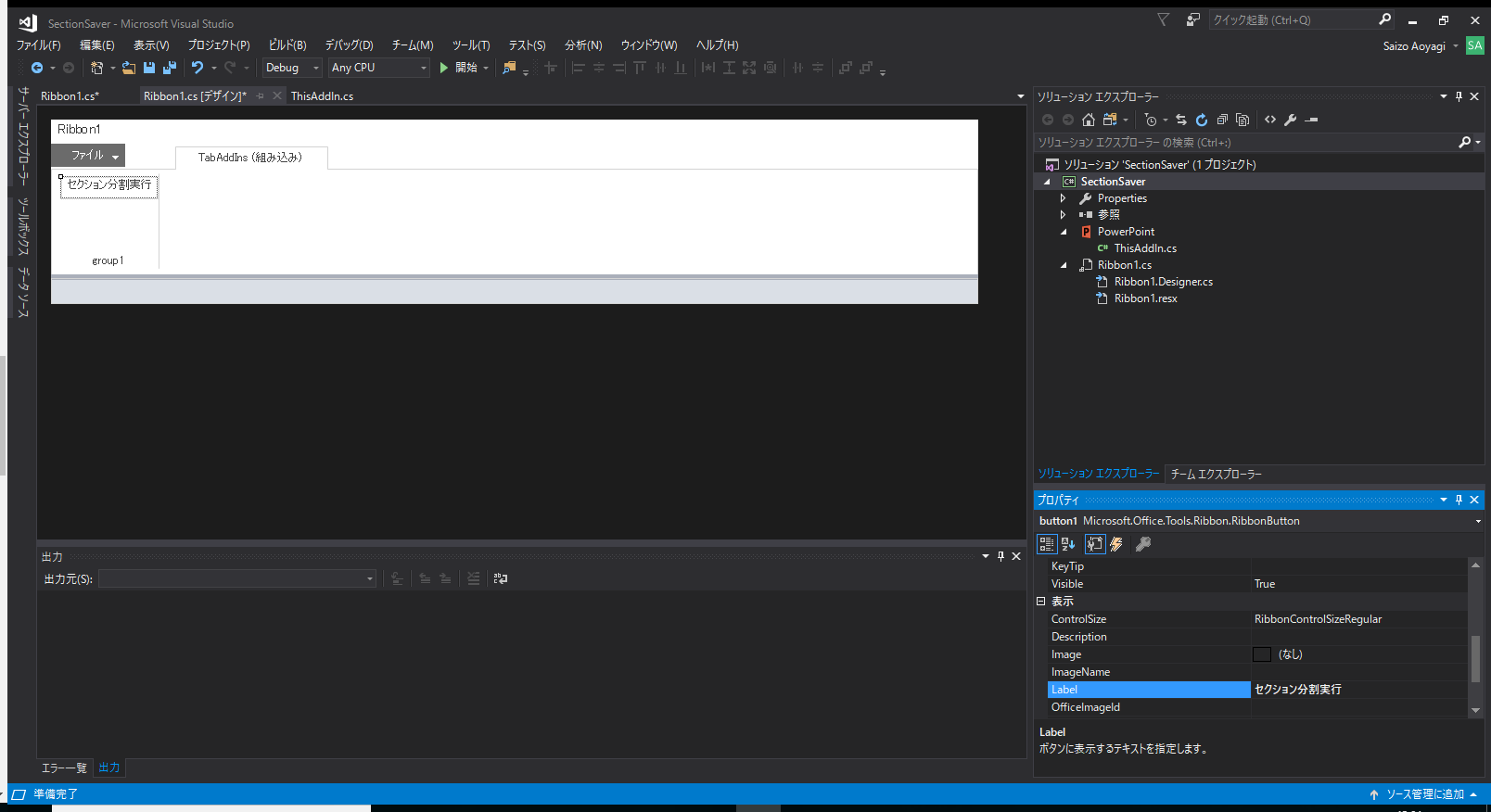
リボンのイメージが表示されるので、左側にある「ツールボックス」を開き、「Office リボンコントロール」の中にあるButtonをイメージの適当な場所にドラッグします。
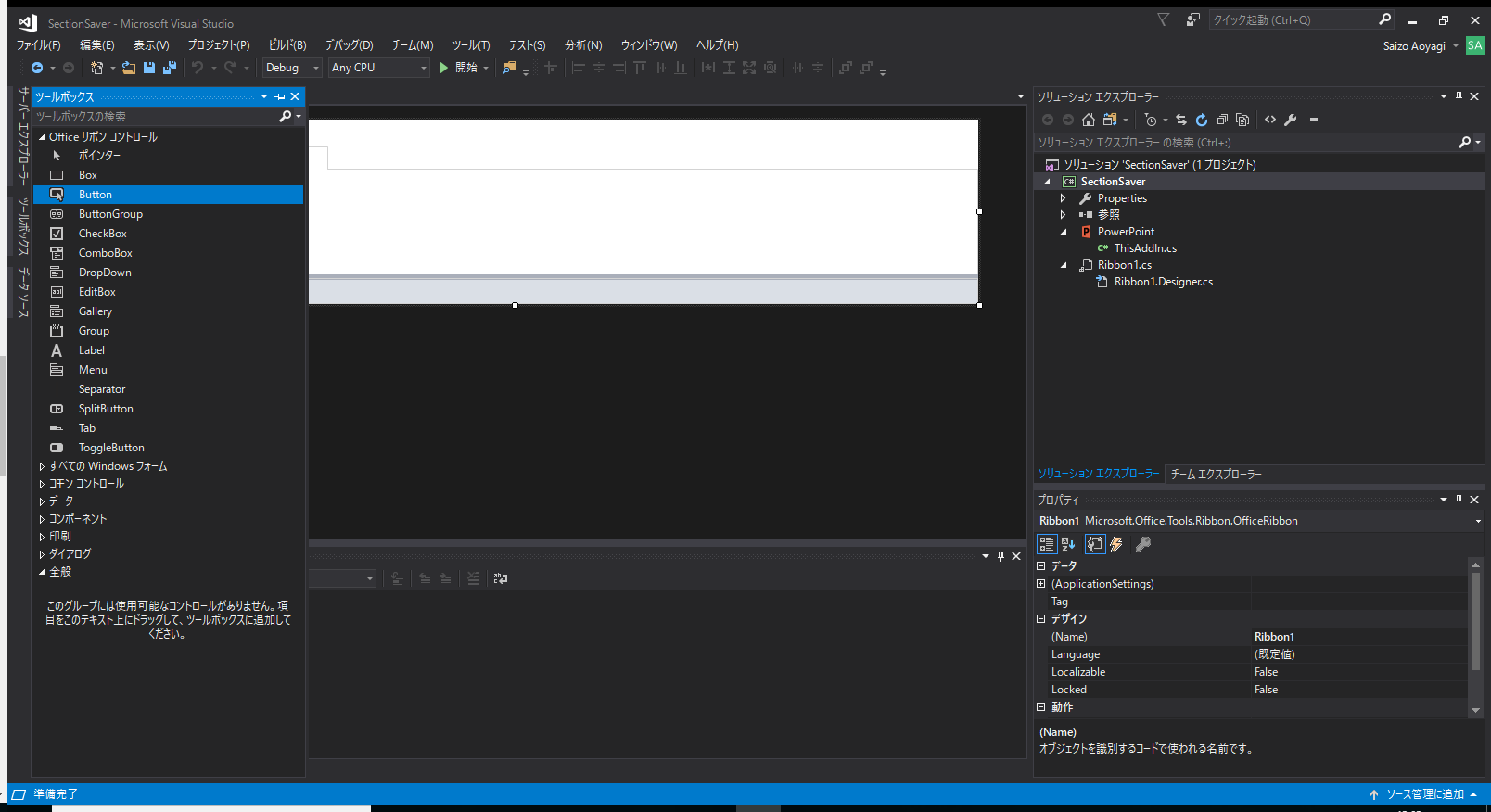
追加したボタンを右クリックし「プロパティ」をクリックし、右下のプロパティ欄を開きます。
「表示」の中の「Label」の欄を「button1」から分かりやすい内容に変更しましょう。
次に、作成したRibbon1を、アドインの開始時に表示します。
ThisAddIn.csに、以下のコードを追加してください。
ThisAddIn.cs
protected override Microsoft.Office.Core.IRibbonExtensibility
CreateRibbonExtensibilityObject()
{
return Globals.Factory.GetRibbonFactory().CreateRibbonManager(
new Microsoft.Office.Tools.Ribbon.IRibbonExtension[] { new Ribbon1(this.Application) });
}
セクションを取得して保存する
上のイメージのペイン内にあるボタンをダブルクリックすると、Ribbon1.csのウインドウが開きます。
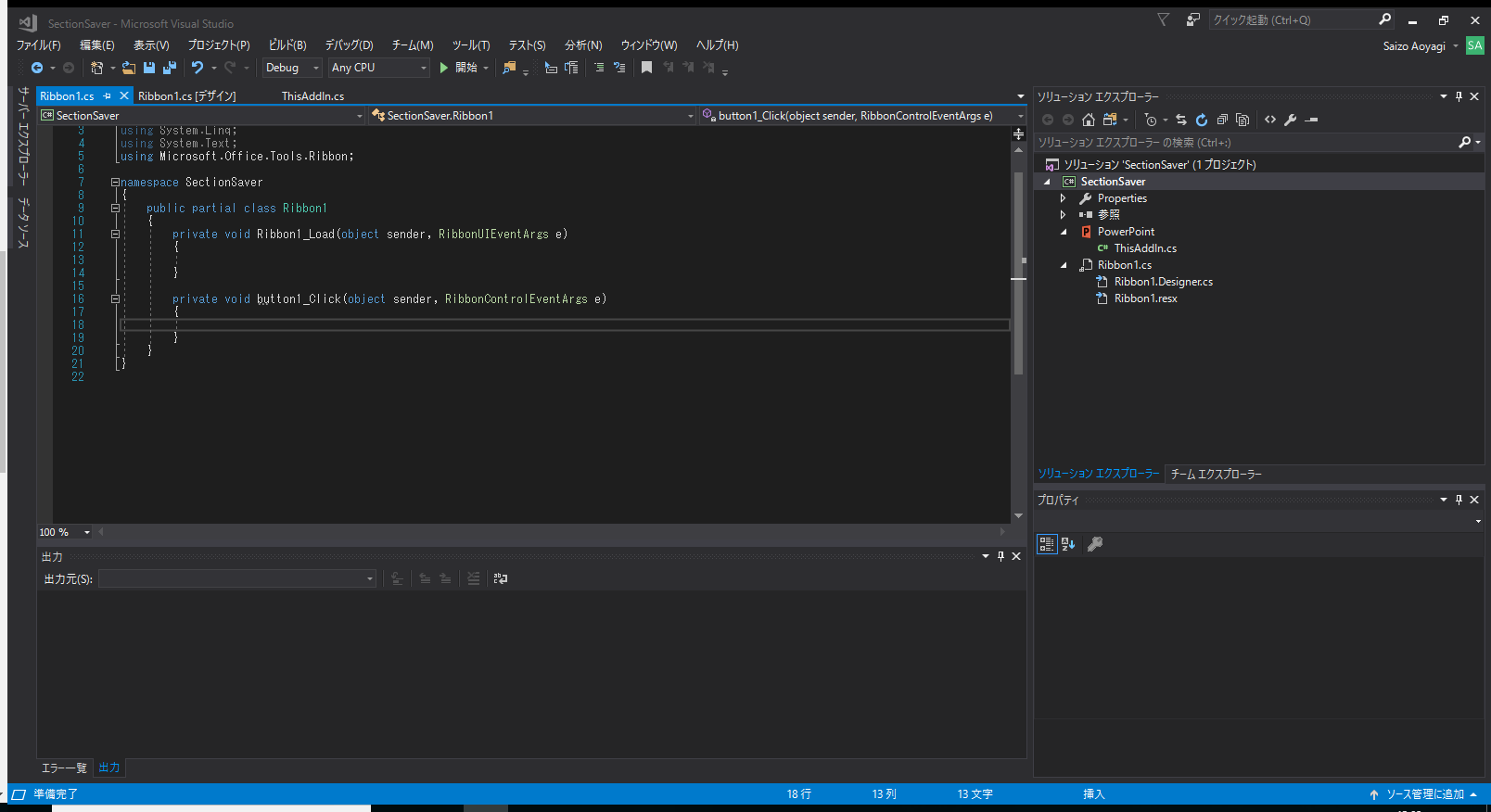
この中の「button1_Click」メソッドに書いた処理が、ボタンのクリック時に実行されます。
以下のように変更しましょう。
Ribbon1.cs
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using Microsoft.Office.Tools.Ribbon;
using Microsoft.Office.Interop.PowerPoint;
using System.IO;
namespace SectionSaver
{
public partial class Ribbon1
{
public Microsoft.Office.Interop.PowerPoint.Application application;
private void Ribbon1_Load(object sender, RibbonUIEventArgs e)
{
}
private void button1_Click(object sender, RibbonControlEventArgs e)
{
int firstSlide;
int slideCount;
Presentation presentation;
Slides originalSlides;
SectionProperties sectionProperties;
application = Globals.ThisAddIn.Application;
sectionProperties = application.ActivePresentation.SectionProperties;
originalSlides = application.ActivePresentation.Slides;
// 保存用フォルダの準備
var baseName = application.ActivePresentation.Path + Path.DirectorySeparatorChar + "parts" ;
bool exists = System.IO.Directory.Exists(baseName);
if (!exists)
System.IO.Directory.CreateDirectory(baseName);
baseName += Path.DirectorySeparatorChar + "my_slide";
// セクションごとの処理
for (var i = 1; i <= sectionProperties.Count; i++)
{
var name = baseName + i.ToString();
firstSlide = sectionProperties.FirstSlide(i);
slideCount = sectionProperties.SlidesCount(i);
presentation = application.Presentations.Add(Microsoft.Office.Core.MsoTriState.msoFalse);
// 内容とデザインのコピー
presentation.Slides.InsertFromFile(application.ActivePresentation.FullName, 0, firstSlide, firstSlide + slideCount-1);
for (var j = 1; j <= presentation.Slides.Count; j++)
{
presentation.Slides[j].Design = originalSlides[firstSlide - 1 + j].Design;
}
application.DisplayAlerts = PpAlertLevel.ppAlertsNone;
presentation.SaveAs(name);
presentation.Close();
}
}
}
}
画面上部の「開始」をクリックして、実行してみましょう。
自動的に、開発中のアドインが読み込まれたパワーポイントが起動します。
「アドイン」タブに、先ほど追加したボタンがあるのでクリックします。

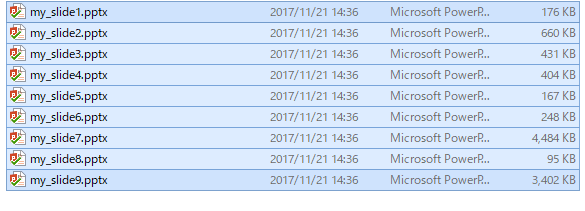
無事に処理が実行され、セクションごとにファイルがわかれました。
参考
チュートリアル : 初めての PowerPoint 用 VSTO アドインの作成(microsoft公式)
https://msdn.microsoft.com/ja-jp/library/cc668192.aspx
リボンの概要(microsoft公式)
https://msdn.microsoft.com/ja-jp/library/bb386097.aspx
リボン デザイナー(microsoft公式)
https://msdn.microsoft.com/ja-jp/library/bb386089.aspx
オブジェクトモデル(microsoft公式)
https://msdn.microsoft.com/ja-jp/library/bb772069.aspx
Slides.InsertFromFile メソッド (PowerPoint)(microsoft公式)
https://msdn.microsoft.com/ja-jp/vba/powerpoint-vba/articles/slides-insertfromfile-method-powerpoint
セクション名一覧を取得するPowerPointマクロ
http://www.relief.jp/docs/013931.html