Python独学ならTech-Joho TOP > Python問題集 >簡単な計算の練習問題(1)
問題
3+11を実行せよ
ただいま、正解判定機能を試運転中です。
実行結果の例
このように表示されるようにプログラムを作りましょう。
3
回答例
答え合わせをしてみましょう。
3 + 11
たくさんのデータで同じ処理を繰り返す | Python独学ならTech-Joho(11)
Python独学ならTech-Joho TOP > Python入門カリキュラム > たくさんのデータで同じ処理を繰り返す
For文とは
For文は、リストのようなたくさんのデータのまとまりの中の、一つ一つについて、同じ処理を繰り返すことのできる文です。
例えば、0から3までの数字をリストにまとめ、それぞれの数字をprint文を使って表示するプログラムを、下のように書くことができます。
>>> for i in [0,1,2,3]:
... print('今の数字:'+str(i))
...
今の数字:0
今の数字:1
今の数字:2
今の数字:3
* for文とは関係ありませんが、str()関数で、整数(int)型の数値を文字列に変えているところに気をつけて下さい。
For文の構造
For文には、どんなFor文でも常に必要な部分と、どのようなデータをどのような繰り返し処理したいか、によって変わる部分があります。
それを図に書いてみました。

この図の白い字の部分、「for」、「in」、「:」の3つはどんなfor文にも必ず出てきます。
この図の赤い字の部分「一つ一つの要素」、「リストなどのデータの塊」、「「一つ一つの要素」を使った処理」の3つは、その時for文を使ってどのようなことをしたいかによって変わります。
例えば、上の0から3の数字を表示する例では、
「一つ一つの要素」が変数”i”、
「リストなどのデータの塊」が整数のリスト”[0, 1, 2, 3]”、
「「一つ一つの要素」を使った処理」が、”print(‘今の数字:’+str(i))”、というpythonの文で、「今の数字:」という文字列のあと、変数iを文字列に変換してprint文で表示しています。
このように、forの後ろには”i”、”value”、”hensuu”のように「一つ一つの要素」を入れる好きな変数名を、inの後ろには「リストなどのデータの塊」を書くことになります。
For文が動く3つのステップ
このfor文の意味、動き方は3ステップに分けて考えると分かりやすいと思います。
- inの後ろに書いた「リストなどのデータの塊」から、順番にデータを1つ取り出す
- 取り出したデータが、forの後ろに書いた「一つ一つの要素」に代入される
- forの下のブロックに書いた「一つ一つの要素」を使って何か処理をする
- ステップ1に戻り、「リストなどのデータの塊」の次のデータを取り出す
- 以下、繰り返し…
0から3の数字を表示するfor文の動きを、このステップ毎に考えてみましょう。
ステップ1:inの後ろに書いた「リストなどのデータの塊」から、順番にデータを1つ取り出す
>>> for i in [0,1,2,3]:
「リストなどのデータの塊」は、inの後ろに書いてあります。
この例だと、”[0,1,2,3]”です。
そこから、順番にデータを一つ取り出します。
まずは、一番最初の”0″です。
ステップ2:取り出したデータが、forの後ろに書いた「一つ一つの要素」に代入される
>>> for i in [0,1,2,3]:
「リストなどのデー
「一つ一つの要素」はforの後ろに書いてあります。
forの後ろは”i”です。
つまり、iに0が代入されます。
このあと、for文の下のブロック(字下げされた部分、つまり「「一つ一つの要素」を使った処理」のところ)では、iは0です。
ステップ3:forの下のブロックに書いた「一つ一つの要素」を使って何か処理をする
... print('今の数字:'+str(i))
「「一つ一つの要素」を使った処理」は、”print(‘今の数字:’+str(i))”、つまり、
‘今の数字:’という文字列を、iという変数に入ってる内容をくっつけてprint文で表示されています。
iは今は0なので、”print(‘今の数字:’+str(i))”は、”print(‘今の数字:0’)”と同じことです。
最終的に、’今の数字:0’と表示されます。
ステップ1に戻り、「リストなどのデータの塊」の次のデータを取り出す
ここまでで、for文の下のブロック(字下げされた部分、つまり「「一つ一つの要素」を使った処理」のところ)が終わりました。
今度は、ステップ1に戻ってまた同じことを繰り返します。
ただし、今度はステップ1では、リストに入っている次のデータを取り出します。
つまり、0のとなりの1です。
先程はiが0でしたが、今度はiに1が代入されます。
すると、最終的に’今の数字:1’と表示されます。
同じ要領で、0, 1, 2, 3とリストの中の数字が順番にiに代入され、そのiを使ってforの下に書いた処理が実行されていきます。
結果として、0から3の数字が全て下のように表示されることになります。
今の数字:0 今の数字:1 今の数字:2 今の数字:3
For文の練習問題
For文の書き方、動き方についてわかりましたか?
練習問題を幾つか用意したので、これをときながら、しっかり理解しているかどうか確認してみましょう。
forとrangeとprintの基本問題(1)
Python独学ならTech-Joho TOP > Python問題集 >forとrangeとprintの基本問題(1)
問題
for文を使って、0から9までの10種類の数字を表示せよ。
ただいま、正解判定機能を試運転中です。
実行結果の例
このように表示されるようにプログラムを作りましょう。
1 2 3 4 5 6 7 8 9
回答例
答え合わせをしてみましょう。
for i in range(0, 10): print(i)
解説
range(0, 10)が、0から9までの整数のリストのような構造のデータを作ります。
0から10までではないのに気をつけて下さい。
その一つ一つの数字が順番にiに代入されます。
For文の中のブロックでは、そのiの内容がprint文で表示されます。
この処理が0から9までの全ての数字に適用されることで、最終的に0から9までの数字が表示されます。
For文については、こちらのページも参考にしてください。
たくさんのデータで同じ処理を繰り返す(第11回)
Pythonでディープラーニングしてみる(AWS Cloud9/Keras)
KerasとCloud9
この記事では、Cloud9で作ったEC2環境に上にKerasをインストールしてディープラーニングを試してみます。
Windowsを使っている等、自分のPCにいろいろインストールしたくない人はこの方法がおすすめです。
(べつにWindowsでもできますが)
Kerasは深層学習用のライブラリの一つです。
他に有名なのはgoogleのTensorflowですが、Kerasは、他にもいろいろあるライブラリを上から使う上位のライブラリという感じです。
この記事でも実際の計算はTensorflowにやらせていますが、Kerasを間にかませることでコードが簡単になります。
機械学習自体の研究者ならともかく、結果を利用するだけなら、Kerasでいいのではないでしょうか。
Cloud9は、Webブラウザ上で使用できるIDE(統合開発環境)ですが、Amazonに買収されAWSのサービスと統合されたので使いやすくなり(?)、注目されています。
詳しくは下の記事をご覧ください。
AWS Cloud9でPython開発する準備
環境の構築
まず、仮想環境を構築します。
この記事のとおりに実行してください。
AWS Cloud9でPython開発する準備
pythonも3に設定します。
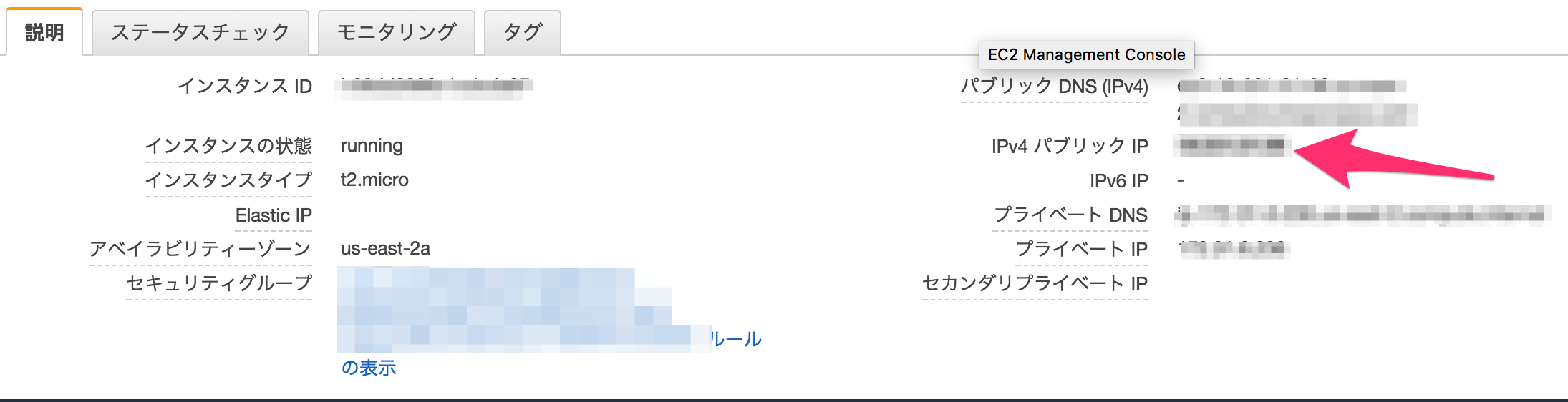
また、EC2のIPアドレスをメモしておきましょう。jupyter notebookにアクセスするのに必要です。
セキュリティ設定
また、Jupyter notebookを使うために、80ではなく8888ポートを開けて置きましょう。
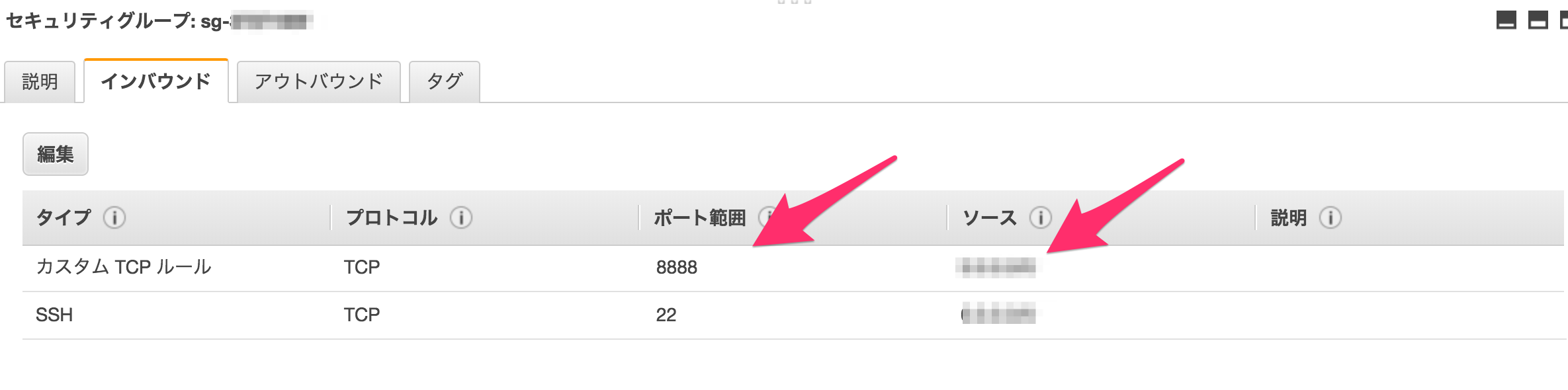
また、他の人のアクセスを防ぐために、パスワード認証をしたり、IPアドレスでアクセス制限をかけましょう。
方法は、下のサイトに詳しいです。
Jupyterをサーバ上で起動する
http://www.mwsoft.jp/programming/numpy/jupyter.html
Jupyter notebookのパスワード
https://qiita.com/SaitoTsutomu/items/aee41edf1a990cad5be6
インストール
tensorflow、keras、jupyternotebookをインストールします。
cloud9のEC2のコンソールで以下を実行します。
$ sudo pip-3.6 install -U tensorflow $ sudo pip-3.6 install -U keras $ sudo pip-3.6 install -U pillow $ sudo pip-3.6 install -U matplotlib $ sudo pip-3.6 install -U jupyter
こんな感じに、画面下のところに入力してコマンドを実行します。

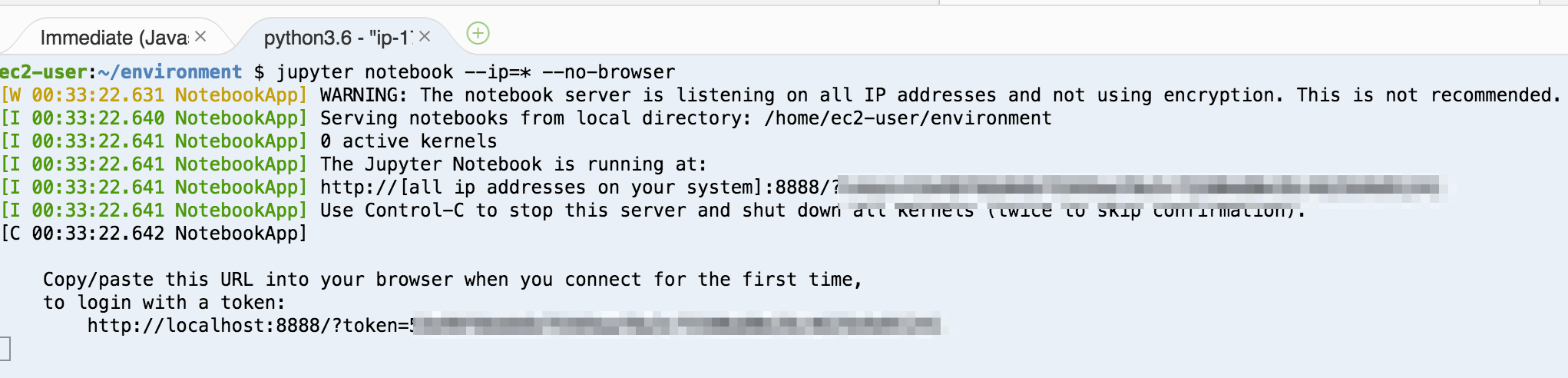
次に、jupyter notebookを起動しましょう。下のコマンドを実行します。
$ jupyter notebook --ip=* --no-browser
こんな感じになれば、jupyterの起動に成功しています。
この時、「token=」の後ろにあるトークンをメモしておきましょう。jupyter notebookのログインに必要です。
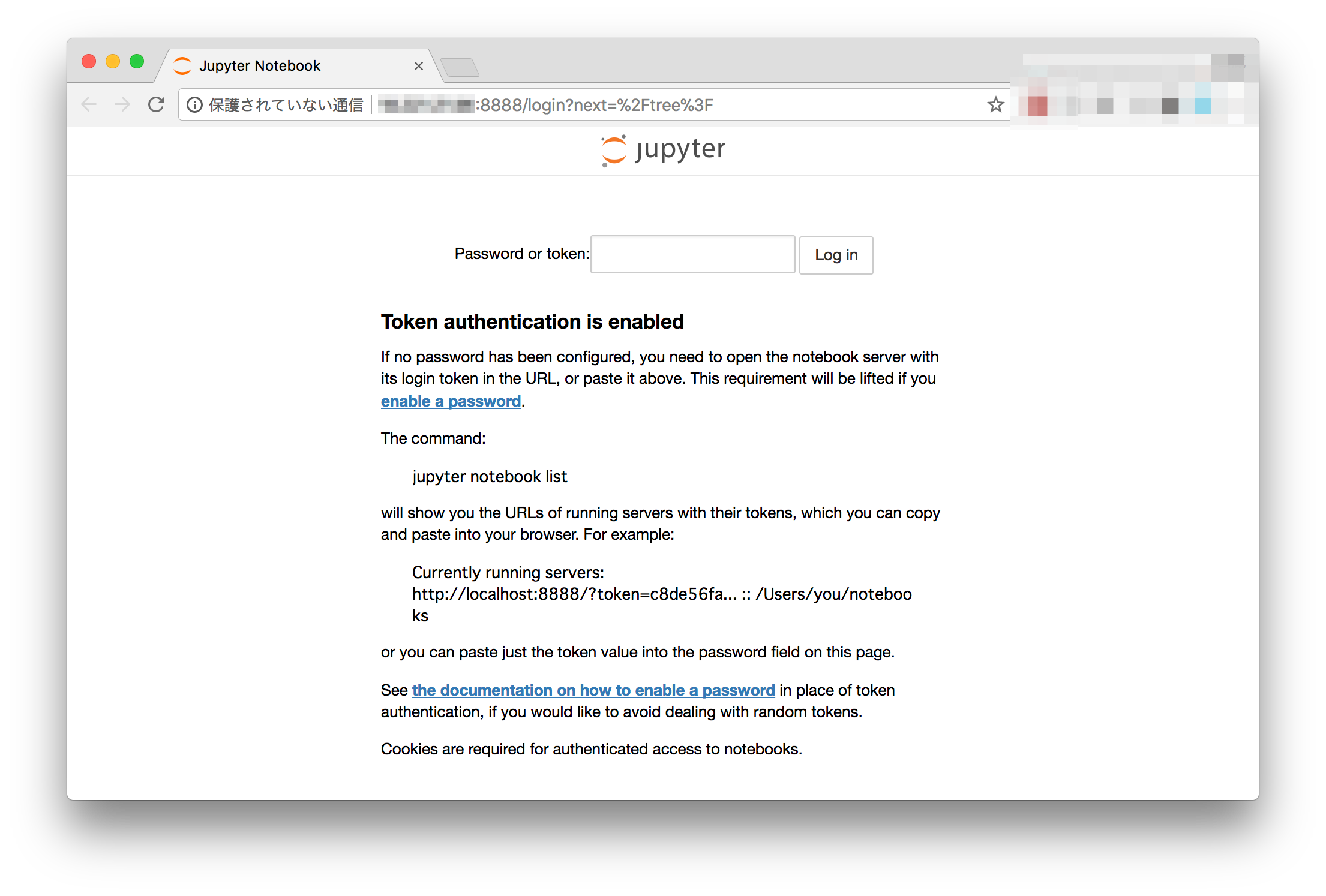
最初にメモしたEC2のIPアドレスの後ろに:8888をつけてブラウザでアクセスすると、下のようなページが開くはずです。
“Password or token”の欄に先程メモしたトークンを入力するとログインできます。
右上にあるNewをクリックし、次にPython3をクリックします。新しいノートが作られます。
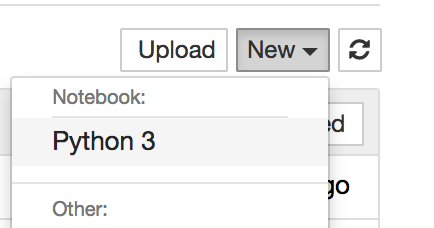
こんな感じです。これで準備完了です。では、 kerasを動かしてみましょう。

最低限のネットワークを動かしてみる
Developpers.IOにのっている、最低限のネットワークを動かしてみましょう。
下のコードをコピーしてノートに貼り付け「Shift+スペース」を押して実行しましょう。
引用元: https://dev.classmethod.jp/machine-learning/introduction-keras-deeplearning/
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers.core import Dense, Activation
from keras.utils import np_utils# Kerasに含まれるMNISTデータの取得
# 初回はダウンロードが発生するため時間がかかる
(X_train, y_train), (X_test, y_test) = mnist.load_data()# 配列の整形と、色の範囲を0-255 -> 0-1に変換
X_train = X_train.reshape(60000, 784) / 255
X_test = X_test.reshape(10000, 784) / 255# 正解データを数値からダミー変数の形式に変換
# これは例えば0, 1, 2の3値の分類の正解ラベル5件のデータが以下のような配列になってるとして
# [0, 1, 2, 1, 0]
# 以下のような形式に変換する
# [[1, 0, 0],
# [0, 1, 0],
# [0, 0, 1],
# [0, 1, 0],
# [1, 0, 0]]
# 列方向が0, 1, 2、行方向が各データに対応し、元のデータで正解となる部分が1、それ以外が0となるように展開してる
y_train = np_utils.to_categorical(y_train)
y_test = np_utils.to_categorical(y_test)# ネットワークの定義
# 各層や活性関数に該当するレイヤを順に入れていく
# 作成したあとにmodel.add()で追加することも可能
model = Sequential([
Dense(512, input_shape=(784,)),
Activation(‘sigmoid’),
Dense(10),
Activation(‘softmax’)
])
# 損失関数、 最適化アルゴリズムなどを設定しモデルのコンパイルを行う
model.compile(loss=’categorical_crossentropy’, optimizer=’sgd’, metrics=[‘accuracy’])# 学習処理の実行
model.fit(X_train, y_train, batch_size=200, verbose=1, epochs=20, validation_split=0.1)# 予測
score = model.evaluate(X_test, y_test, verbose=1)
print(‘test accuracy : ‘, score[1])
これは、MNISTというデータベースを使い、手書き数字の画像に何の数字がかかれているか判別する判別器をつくるというコードです。
THE MNIST DATABASE of handwritten digits
http://yann.lecun.com/exdb/mnist/
こんな風に貼り付けます。

実行すると、ずらずらと数値がでてきます。学習を進めている様子が出力されています。一番下にでてきたtest accuracyが最終的な正解率です。
この例では、0.8901です。あまり良くありません。
DeepLearningやニューラルネット自体の解説は長くなるので他の記事を参考にしてください。
判別させてみよう
上の例をコピペして動かしただけでは、ディープラーニングデキた!という感じがしないと思いますので、今作ったモデルを利用して、実際に手書きで数字を書いて、何の数字が書いてあるか判別させてみましょう。
まず、ペイントなどで数字を書きます。それを、MNISTのフォーマットと同じ28×28のサイズのBMP画像として保存しましょう。
この画像ファイルをブラウザのcloud9のタブの左側、ファイルの一覧にドラッグ&ドロップでアップロードしましょう。
こんな風にアップロードできます。
次に、このファイルを読み込んでみましょう。
Jupyter notebookのウインドウを開き、入力欄に以下のコードを入力して「Ctrl+スペース」で実行します。
(3.bmpとなっているところにあなたがアップロードしたファイル名をいれてください。)
from PIL import Image
import matplotlib.pyplot as plt
import numpy as np
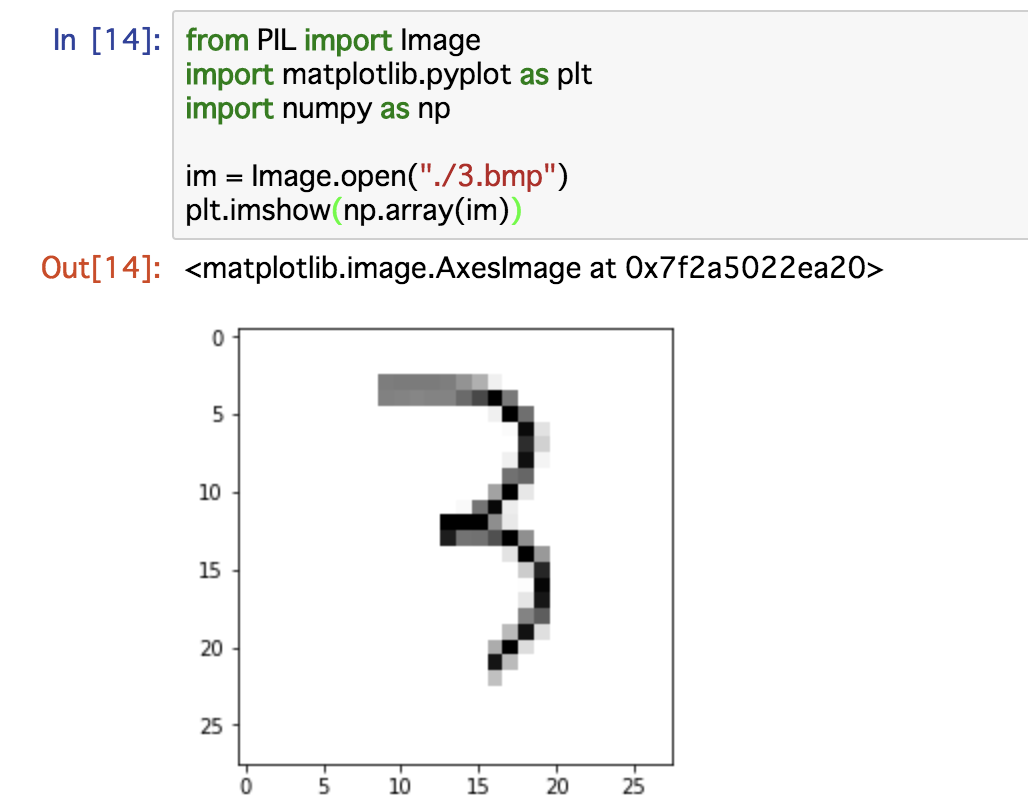
im = Image.open("./3.bmp")
image_array = np.array(im)
plt.imshow(image_array)
こんな風に表示されます。
では、この手書き文字が何の数字を書いてあるのか、ニューラルネットに予測させてみましょう。
下記を入力して実行してください。
(なお、#学習データ4を判定と書いてある行のコメントアウトを外せば、学習に使ったデータから画像を抜き出して判定できます)
from PIL import Image
import matplotlib.pyplot as plt
import numpy as np
im = Image.open("./3.bmp")
# グレースケールに変換
rgb = im.convert('RGB')
im2 = Image.new('L',(28,28))
for x in range(28):
for y in range(28):
r,g,b = rgb.getpixel((y,x))
gray= 255-int((r + g + b)/3)
#gray =int( X_test[4,x*28+y]*255) # 学習データ4を判定
im2.putpixel((x,y),(gray))
# イメージの表示
image_array = np.array(im2).T
plt.imshow(image_array)
# 予測
np.set_printoptions(suppress=True)
np.set_printoptions(precision=2)
target_array = image_array.reshape(1,784)
classes = model.predict(target_array, batch_size=1)
print(classes)
こんな結果が表示されました。
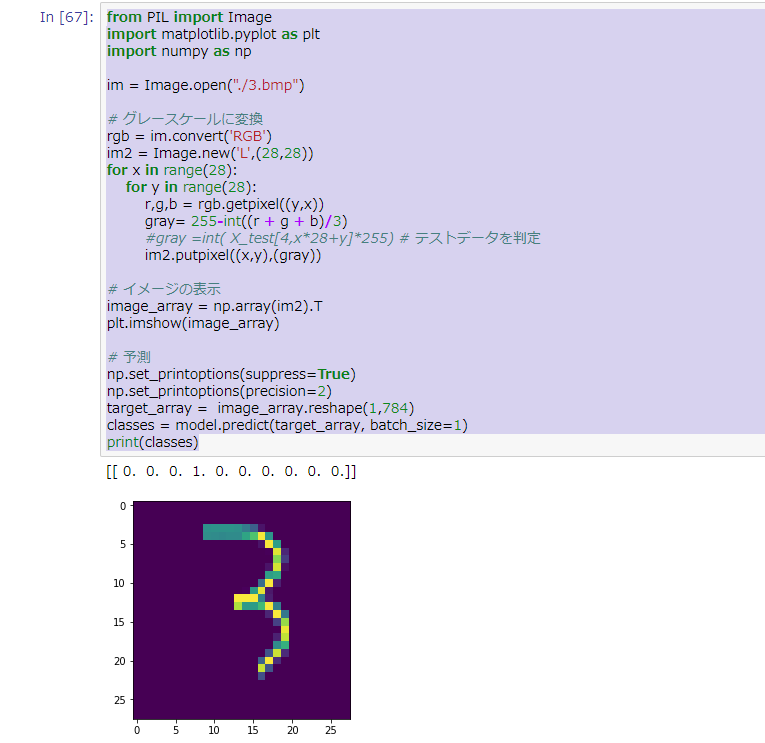
この結果は、左から、読み込ませた文字が0の確率、1の確率、2の確率…と並んでいます。
この結果によると100%の確率で、3とでました。
きちんと認識できていそうです。
ただし、他の画像だと完全に間違っていることもあります。
まだそんなに精度が高くないせいでしょうか。
このあたりのモデルの改善はまた別の機会にやってみましょう。
Turtleを使ってpythonで絵を描く
Python独学ならTech-Joho TOP > いろいろやってみた > Turtleを使ってpythonで絵を描く
Turtleモジュール
Pythonで絵を描く、となればまずはTurtleモジュールです。
より高度なPygameやKivyを使った方法も別ページ紹介しています。
Turtleモジュールは、ペンを持った亀を操って絵を描くことのできるタートルグラフィックスのPython版です。
参考
タートルグラフィックス (公式ドキュメント)
https://docs.python.jp/3/library/turtle.html
このページでは、下の黒い欄で、実際にPythonコードを実行できます。
この後の説明の通り、自分でも絵を書いてみましょう。
まず、下のリンクをクリックして、お絵かきウインドウを別に開いて下さい。
お絵かきウインドウを開く
お絵かきウインドウは、このようになっています。

左の方に黒い欄があります。
ここに、Pythonコードを書いていきます。
黒い欄の使い方はこちら
右に白いスペースが開いていますが、ここに絵が出力されます。
まず円を描いてみよう
さっそくですが、まず円を描いてみましょう。
下のコードを、お絵かきウインドウの黒い欄に1行ずつコピー&ペーストして、エンターを押していってください。
>>> import turtle >>> t=turtle.Turtle() >>> t.circle(100) >>> turtle._Screen().end()
こんな風に、円が描かれたはずです。
Turtleモジュールではこのようにコードを入力することで絵を描くことができます。

上のコードを1行ずつ解説していきます。
>>> t=turtle.Turtle()
この行では、turtleモジュールを読み込んでいます。
turtleモジュールには、絵を描くための様々なクラスや関数が入っています。
これを利用できるように読み込んでいます。
>>> import turtle
この行では、 先程読み込んだturtleモジュールの中に入っているTurtleというクラスのインスタンスを作っています。
筆を持った亀を一匹呼び出すイメージです。
この亀は、変数tに代入しています。
変数tに入っている、亀(Turtleクラスのインスタンス)の様々なメソッドを実行することで、この後絵を書いていきます。
>>> t=turtle.Turtle()
この行では、変数tに入っている、亀(Turtleクラスのインスタンス)に、半径100の円をかけ、と命令しています。
円を書く命令なので、circleという名前のメソッドを実行しています。
また、cicrleメソッドの引数は半径です。半径100なので、カッコの中に100と書いてあります。
>>> t.circle(100)
この行では、今まで入力した命令を、実行しろ、という命令をだしています。
そのため、この行を実行すると、円が描かれます。
ただし、この行は、通常のPythonでは必要がありません。
このサイトのように、ブラウザ上で動かすPython(Brython)の場合だけ、必要な内容です。
>>> turtle._Screen().end()
Turtleモジュールのいろいろな使い方
まず、お絵かきウインドウをリロードして下さい。
今までの内容が全て消えます。
次に、下の内容を全てコピーして、お絵かきウインドウの黒い欄にペーストし、エンターを押してください。
このように、1行ずつでなく、一気に複数行を実行することができます。
import turtle
t=turtle.Turtle()
t.shape("turtle")
t.color("red")
t.forward(100)
t.penup()
t.left(90)
t.forward(100)
t.right(90)
t.pendown()
t.width(5)
t.color("blue")
t.forward(100)
turtle._Screen().end()
このように、線が2本表示されたと思います。
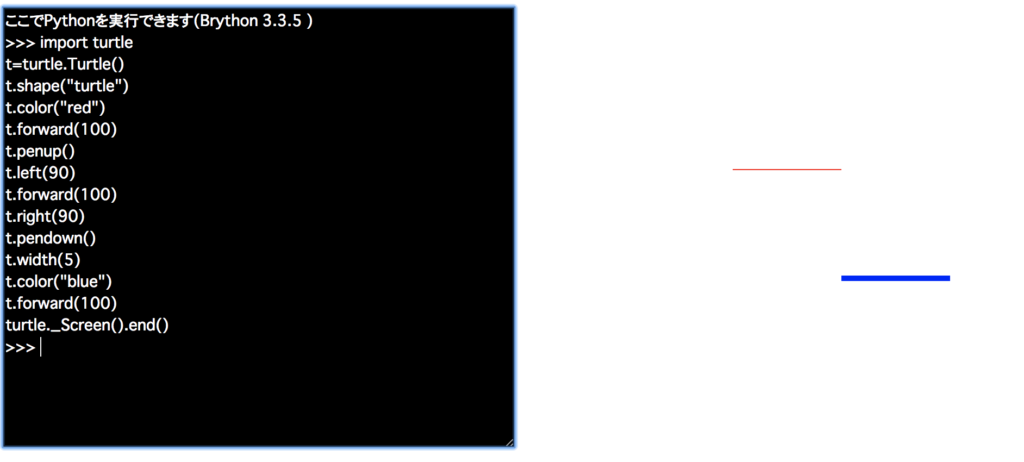
一番最初の”t=turtle.Turtle()”と、一番最後の”turtle._Screen().end()” の部分は前と同じです。
それ以外のところはだいぶ違いますね。
ここでは、新しいテクニックを5つ(とおまけ1つ)使っています。
真っ直ぐ進む
タートルグラフィックスでは、亀のアイコンが常に筆を持って移動しているイメージです。
亀が移動すると、そのあとには線が引かれます。
forwardというメソッドを使うと、亀が真っ直ぐ進み、線を引きます。
引数の数値のぶんだけ進みます。
下では、100進んでいます。
t.forward(100)
向きを変える
right、leftというメソッドで、右左に向きを変えられます。
引数には、曲がる角度をしてします。
下の例では、90度右に曲がっています。
t.right(90)
線の色を変える
colorメソッドを使います。
引数に英語で色の名前を指定します。
下の例では赤色にしています。
t.color("red")
ペンを上げて移動する
今まで、亀が移動すると必ず線が引かれていましたが、penup関数を使うと、その後は線が引かれなくなります。
線を引かずに移動だけするのに便利です。
また、pendown関数を使うとまた、線が引かれるようになります。
t.penup() t.pendown()
ペンの太さを変える
width関数を使うと、先の太さを変えられます。
引数は太さの数値です。
t.width(5)
おまけ:アイコン亀にする
線を引いているときの、アイコンが矢印ではなく亀になっていたのに気づきましたか?
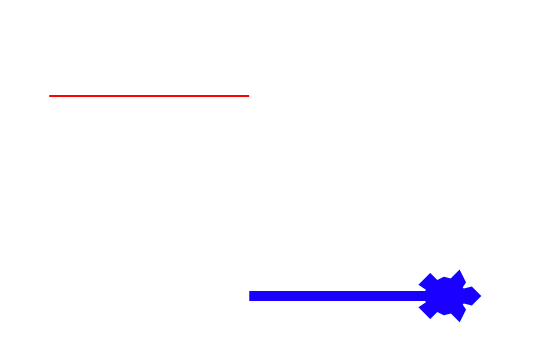
これは、3行のshapeメソッドで変えています。
import turtle
t=turtle.Turtle()
t.shape("turtle") # 亀にしている
このようなテクニックを使えば、いろいろな絵がかけるはずです。
タートルグラフィックスで描いた例
下の絵は、PythonをPC内にインストールした時についてくる、タートルグラフィックスのサンプルです。
詳しくはこちらに説明があります。
このような絵を、このページにあるテクニックで描くことができます。
みなさんも、ぜひ、好きな絵をかいていみてください。
実際に動く時計です。
実物はくるくるとアニメーションします。
PythonスクレイピングツールScrapyで定期的に情報取得
Python独学ならTech-Joho TOP > いろいろやってみた >PythonスクレイピングツールScrapyで定期的に情報取得
PythonでWebサイトに書いてある情報を取得する
プログラムを使って、Webサイトに書いてある情報を取得することがスクレイピングです。
いわゆるクローリングにも近い概念です。
Pythonで実施することができ、その方法も色々ありますが、お手軽なのがScrapyというツールを使うことです。
Scrapy公式ページ
https://scrapy.org/
インストールするには、pipで以下のように実行します。
> pip install Scrapy
Scrapyの基本的な使い方
Scrapyのいちばん大事なWebページにアクセスして書いてある内容を読み取る機能は、SpiderというPythonのクラスに集約されています。
これを継承したオリジナルのクラスを作成するのが、Scrapyを使う最初の一歩です。
例えば、Yahoo! Japanのニュースのページにアクセスして、一番上のニュース欄にある見出しを取得・表示してみます。
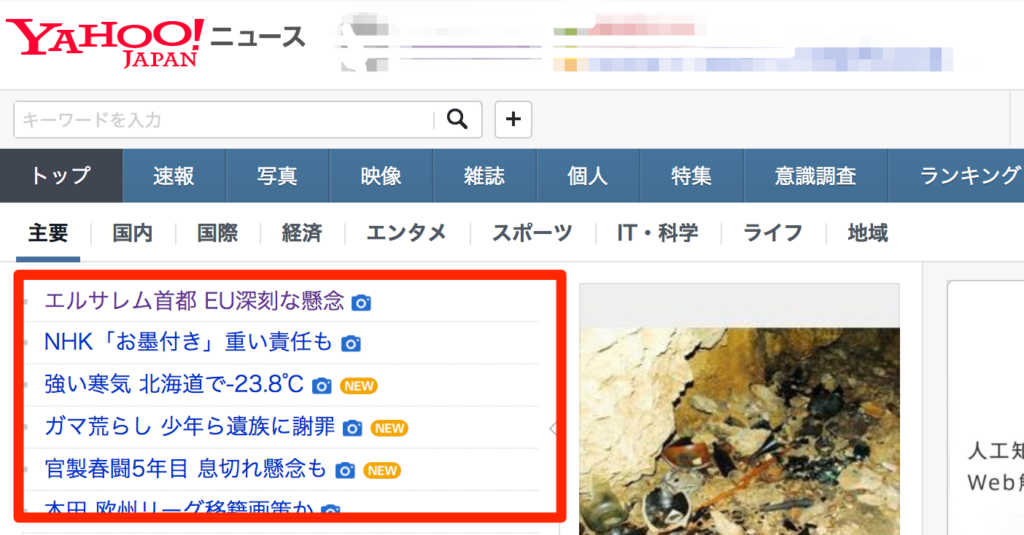
以下のようなファイル yahoospider.py を作成します。
yahoospider.py
import scrapy
class YahooSpider(scrapy.Spider):
name = 'yahoospider'
start_urls = ['https://news.yahoo.co.jp/']
def parse(self, response):
print("start")
for title in response.css(".topics .ttl a::text"):
print(title.extract())
ポイントは parseメソッドで、response.css()をつかって、CSSセレクターでニュースのタイトルの要素を探しています。
“.topics .ttl a::text”というCSSセレクターは、topicsクラスを持つ要素の下のttlクラスを持つ要素の下のa要素のテキストすべて、という意味です。
これを実行するには、コマンドプロンプトなどで以下のコマンドを実行します。
> scrapy runspider yahoospider.py
たくさん文字が表示されますが、中程にニュースタイトルがでてくるはずです。
略 2017-12-07 09:22:59 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) start エルサレム首都 EU深刻な懸念 NHK「お墨付き」重い責任も 強い寒気 北海道で-23.8℃ ガマ荒らし 少年ら遺族に謝罪 官製春闘5年目 息切れ懸念も 本田 欧州リーグ移籍画策か 宇野余裕 寝坊も寝癖もなんの 瀬戸康史 美しい女装男子役 略
Scrapyの機能はたくさんあるのですが、基本的にはこれで十分ではないでしょうか?
繰り返し実行してみた
1分毎や1時間ごとなど、あるサイトに定期的にアクセスして情報の変化を追いたい事があると思います。
これもいろいろな方法がありますが、素朴な方法として、上記のコマンドをタイマーを仕込んだpython経由で実行する方法を書いてみました。
repeat.py
from subprocess import call
import os
import time
dir_path = os.path.dirname(os.path.realpath(__file__))
os.chdir(dir_path)
while True:
call(["scrapy", "runspider", "yahoospider.py"], cwd=dir_path)
print('run spider')
time.sleep(30)
下記のコマンド実行で、30秒に1回、yahooニュースの情報を取得します。
> python repeat.py
上のコードはこちらからダウンロードできます。
https://github.com/tech-joho-info/scrapy-sample-news-site
上のプログラムを改造すれば、いろいろなサイトに応用できます。
是非試してみて下さい。
ただし、あまり頻繁にアクセスするとサイバー攻撃になってしまいますので、気をつけて下さい。
AWS Cloud9でDjangoアプリを作成| Django 入門
AWS Cloud9でDjangoアプリを作成する
この記事の続きです。
https://tech-joho.info/aws-cloud9でpython開発する準備
Djangoアプリを作成して、最初の画面を表示します。
Cloud9でPython3を使う
実は、Cloud9で作った環境では、ディフォルトのPythonはバージョン2です。
これでは、Djangoアプリを作成できないので、まず、Python3を使いやすいように環境を整えます。(実は下の方法でDjangoを起動するのには必要ない)
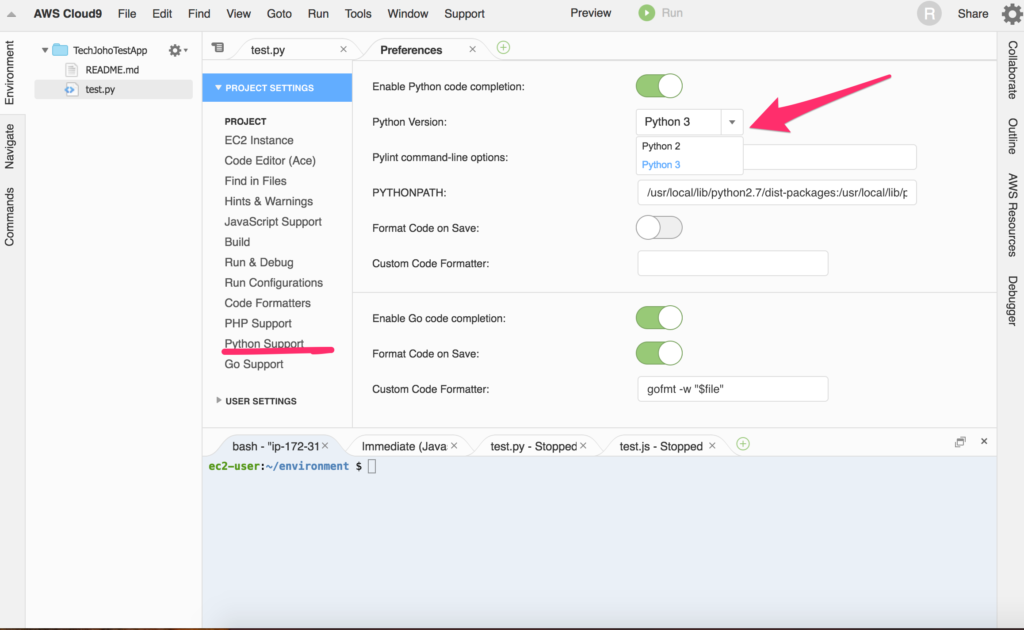
画面左上の”AWS Cloud9″をクリックし、メニューの”Preferences”をクリックしましょう。
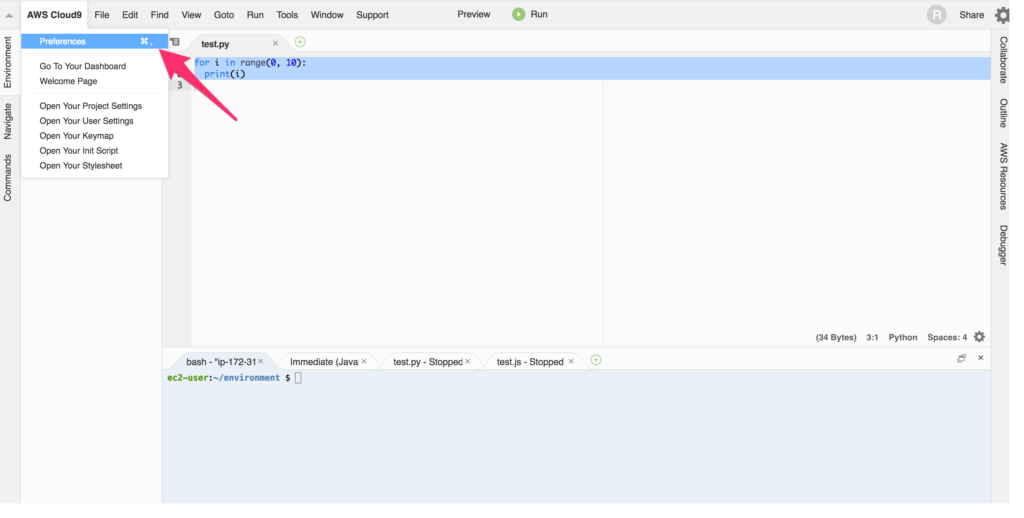
開いた設定タブの左側のメニューの”Python Support”を選択し、Python versionをPython3に変更します。
参考
Cloud9でPython3のDjango環境を5分でつくる
https://qiita.com/rmiyamoto/items/4143c6081fb664208e06
Djangoのインストール
Python3のpipでDjangoをインストールしましょう。
コンソールで下記コマンドを実行しましょう。
$ sudo pip-3.6 install django
Djangoプロジェクトの作成
Djangoプロジェクトを作成します。
コンソールで下記コマンドを実行しましょう。MyTestAppはプロジェクト名です。他の名前でも大丈夫です。
$ django-admin startproject MyTestApp
コマンドを実行すると、プロジェクト名と同じ名前のディレクトリが作成されます。

コンソールで下記コマンドを実行し、プロジェクトフォルダに移動しましょう。
$ cd MyTestApp
Djangoアプリサーバの起動
アプリサーバを起動し、画面を確認してみましょう。
コンソールで下記コマンドを実行しましょう。
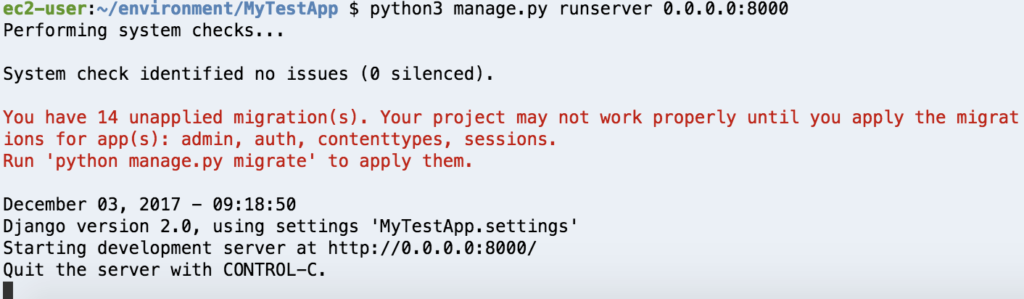
$ python3 manage.py runserver 0.0.0.0:8000
コンソールにこんな内容が表示されれば起動は成功です。
ただし、アプリサーバは起動していますが、まだAWSのファイアーウォールとdjangoのホスト制限のせいで外部からアクセスできません。
これからその設定をしていきます。
セキュリティグループを設定してポートを開ける
まず、AWSのEC2の設定画面に移動しましょう。
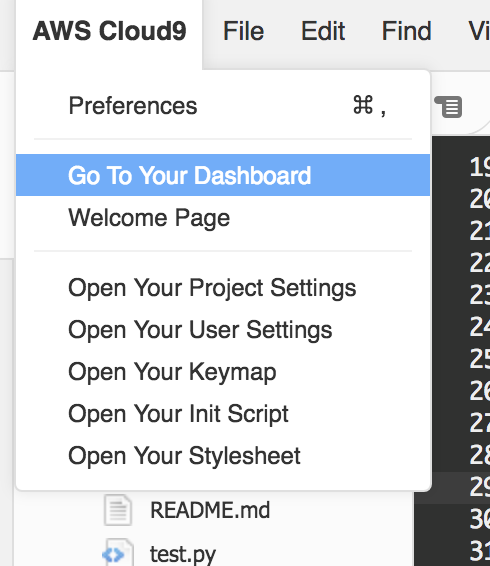
画面左上の”AWS Cloud9″をクリックし、メニューの”Go To Your Dashborad”をクリックしましょう。
別タブで、Cloud9のダッシュボードが開きます。
ダッシュボード左上の「サービス」をクリックし、表示されたメニューの”EC2″をクリックします。
EC2のダッシュボードが表示されるので、「実行中のインスタンス」をクリックします。

EC2インスタンスの一覧が表示され、1つしかない場合、選択状態になっています。
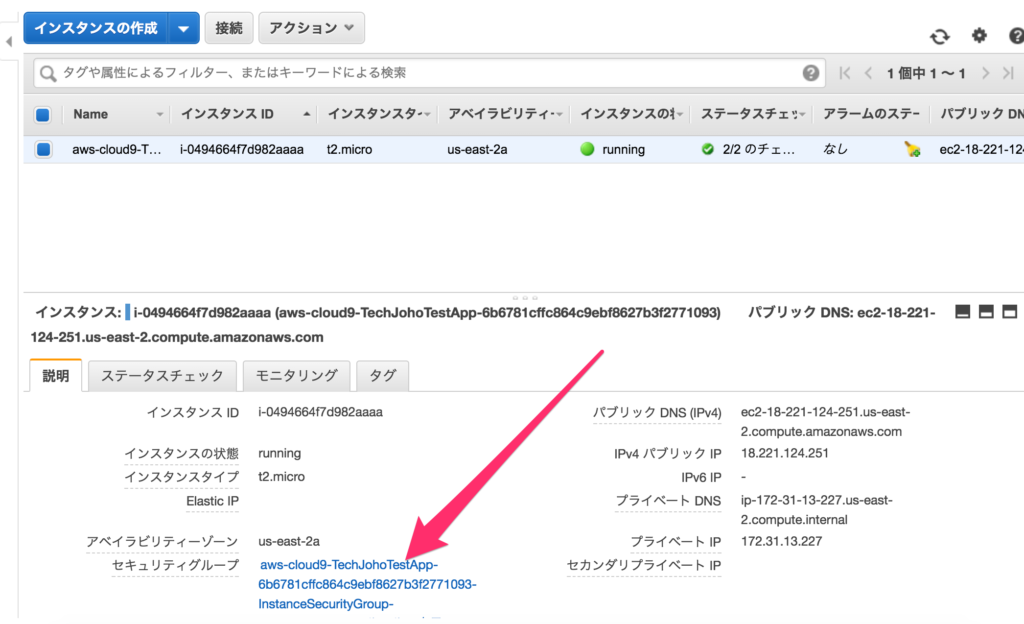
画面下部にはその詳細が表示されていますが、そのうち「パブリック DNS (IPv4)」の欄に表示されているのが、URLの中央部(ホスト)になります。
この前に”http://”を、後に”:8000″をつけてアクセスしてください。
次に、セキュリティグループの欄をクリックします。
セキュリティグループの設定が表示されるので、インバウンドタブを開き、 「編集」をクリックします。
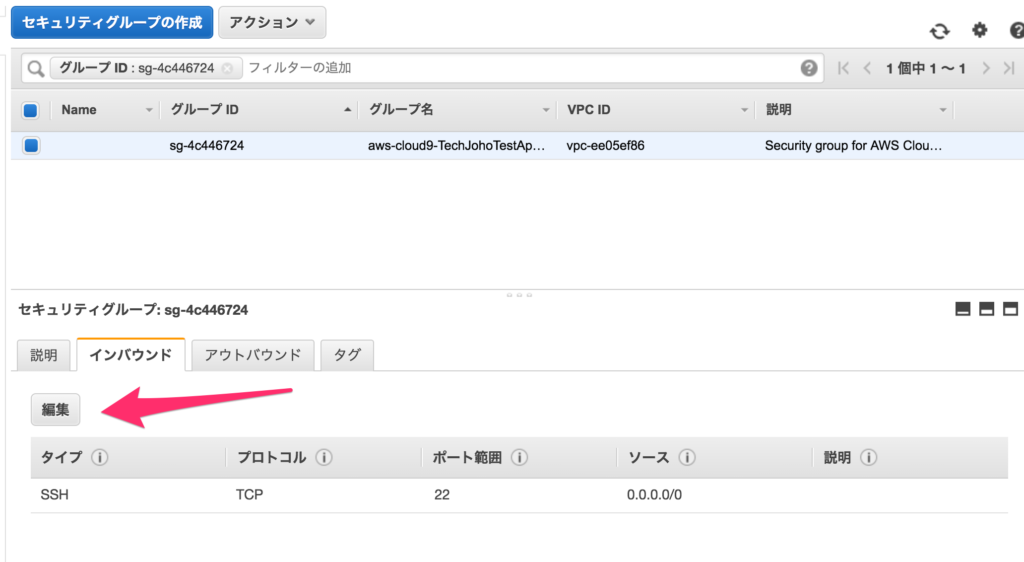
インバウンドルールを設定するダイアログが表示されるので、「ルールの追加」をクリックし、TCPカスタムを選択し、ポートの欄に8000を入力します。最後に、追加をクリックします。これで、ファイアーウォールの設定画変更され、8000番ポートのアクセスが許可されます。
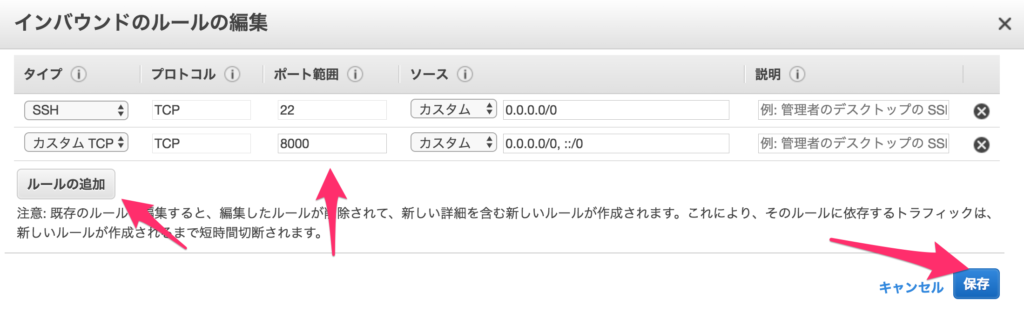
上記の、「パブリック DNS (IPv4)」の欄に表示されている内容に、前に”http://”を、後に”:8000″をつけてアクセスしてください。
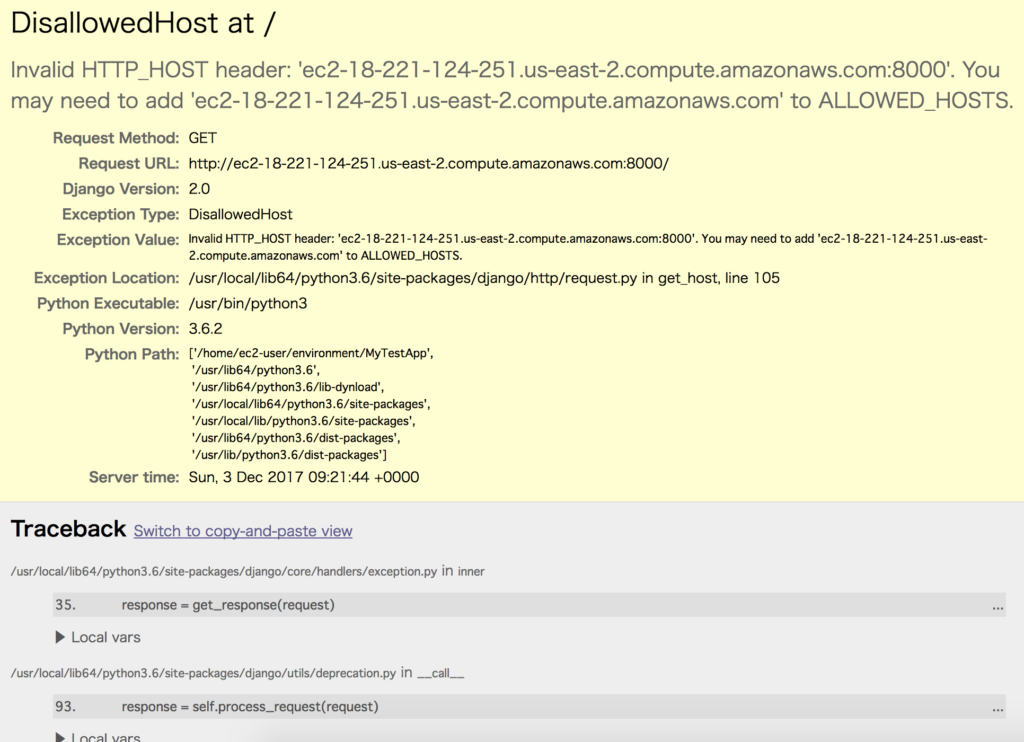
この時点で、Djangoのアプリにアクセスすることができます。
ただし、ホスト制限に引っかかり、下記のようなエラーが表示されます。
DjangoのALLOWED_HOSTSを設定する
まず、開きっぱなしのCloud9のIDEで、MyTestAppディレクトリにあるmanage.pyを開きます。
その中ほどまでスクロールし、ALLOWED_HOSTSというリストに、先程の「パブリック DNS (IPv4)」の欄に表示されている内容を追加します。
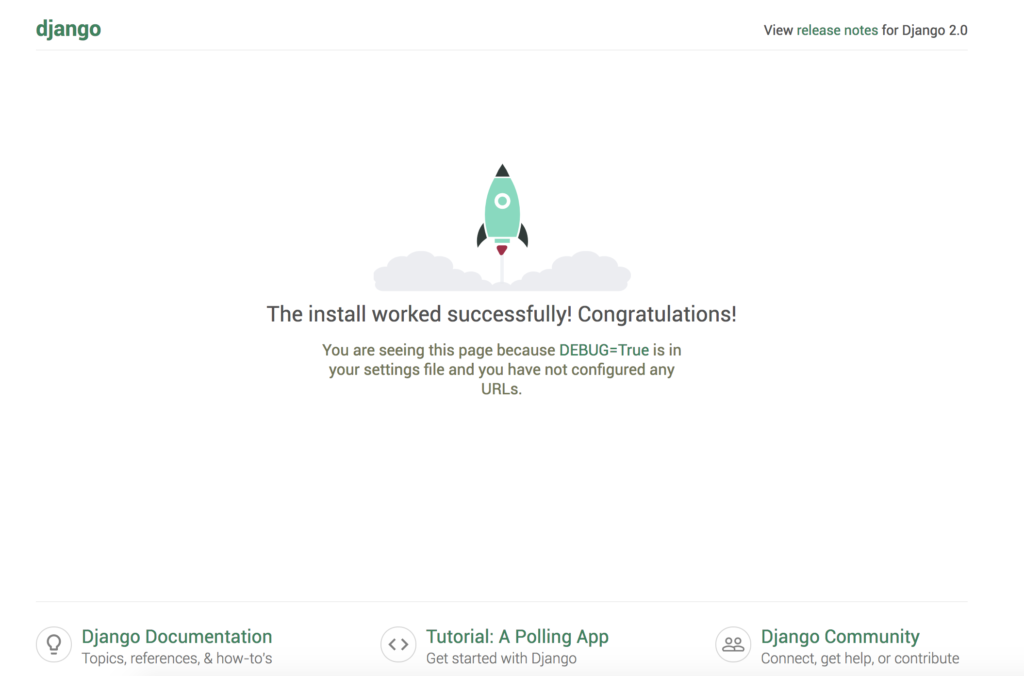
もう一度、:8000で終わるURLにアクセスして下さい。
下のように、Djangoの初期画面が表示されれば成功です。
まだ、EC2やSecurityGroupとの連携がないせいで、結構めんどくさいですね。(2017年12月3日時点)
しかし、そのうち解消されるような気もします。
AWS Cloud9でPython開発する準備 | Django 入門
Python独学ならTech-Joho TOP > django入門 > AWS Cloud9でDjango起動
AWS Cloud9とは
Cloud9は、ブラウザ上で利用可能なIDE(Integrated Development Environment、統合開発環境)です。
JavaScriptやPython等、様々なプログラミング言語のプログラミング、実行、デバッグができます。
もともとは独立した会社が運営していましたが、2017年初頭にAmazonに買収されたようです。
Cloud9
https://aws.amazon.com/jp/cloud9/
Cloud9の公式ドキュメント
https://docs.aws.amazon.com/cloud9/latest/user-guide/welcome.html
Djangoの開発環境としてのCloud9
このサイトでは、WindowsでのDjango開発方法について公開しています。
しかし、実は、Djangoの開発をWindowsですることは、余りおすすめできません。
Djangoを使って開発したアプリを公開する時に、実際に配置するサーバがWindowsであることがほとんどないからです。
大抵はLinuxのUbuntuかCentOSになります。
そして、開発環境と公開するための本番環境はなるべく同じにするべきです。
開発環境でせっかくつくったものが、本番環境ではうごかないことを防ぐためです。
(ちなみに、OSだけでなく、Pythonやライブラリのバージョンなど、開発環境と本番環境で揃えるべきポイントは他にもたくさんあります)
しかし、いろいろな事情でWindows環境で開発しなくてはならない場合もあると思います。
その時、ブラウザ上で動くCloud9なら、ブラウザを動かすOS自体はWindowsでもMacでもなんでも構いません。
また、実際に開発中のアプリが動くのは、EC2上のAmazonLinuxなので、そのままEC2を本番環境にも使用すれば問題は少なくなります。
もちろん、AmazonLinx以外にも利用できます。
そこで、Cloud9を使ってDjangoのアプリケーションを開発してみましょう。
Cloud9をはじめてみる
まず、AWSのアカウントを持っていない人は、アカウントを作りましょう。
注意点としては、必ずクレジットカードが必要です。
Cloud9によるdjango開発の過程で、EC2の環境へのデプロイを選択した場合には、EC2のインスタンスの利用料金がかかります。
しかし、AWSはアカウントを作ってから1年間は無料枠というものがあり、ある程度は無料で利用できます。(2017年12月3日現在)
アカウントを作成したら、ログインしましょう。
https://aws.amazon.com/jp/cloud9/
上記のリンク先にアクセスし、右上の”Sign in to the Console”をクリックして下さい。(なお、2017年12月現在、Cloud9は英語版のみのようです。)
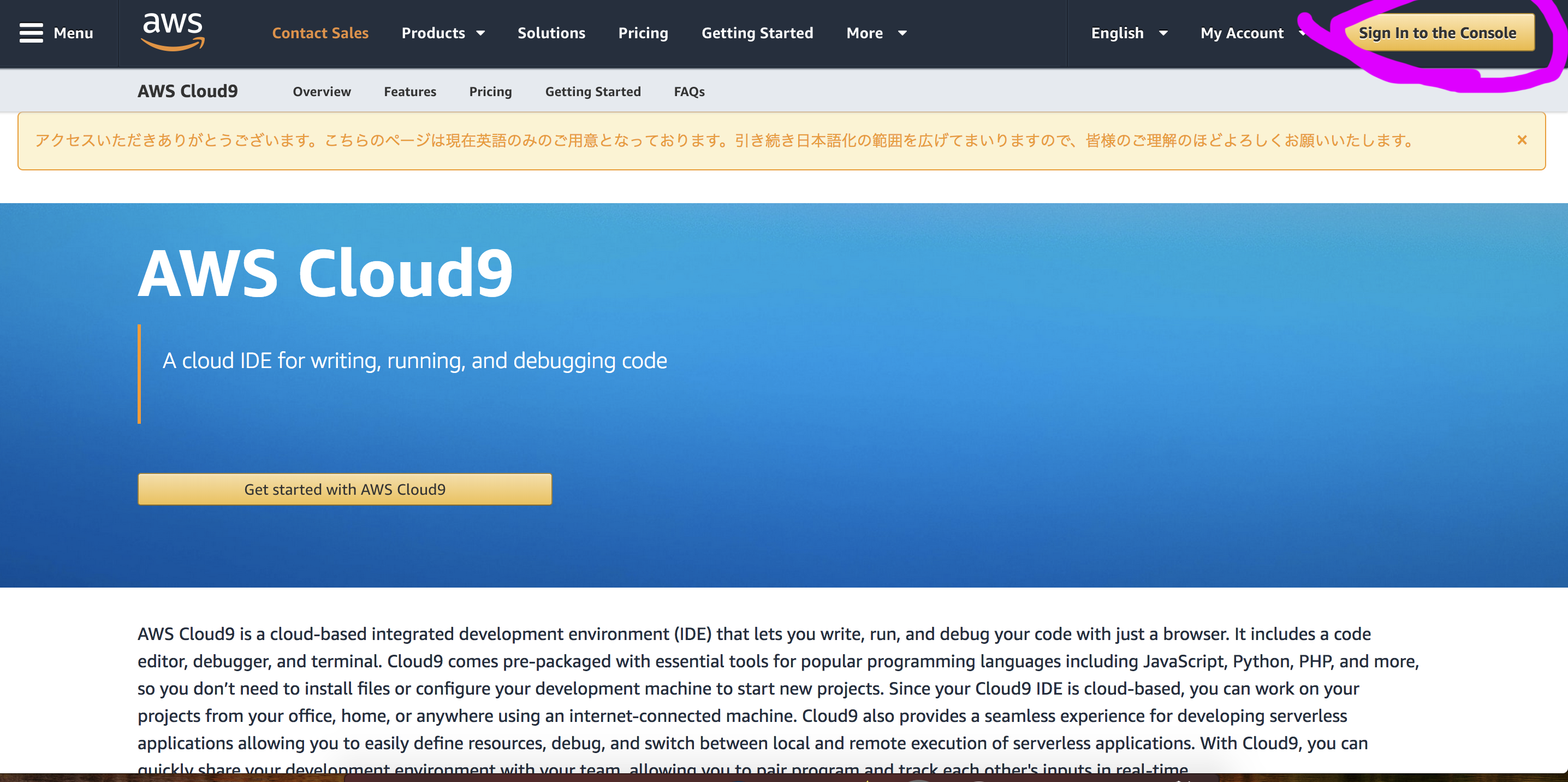
先程作成したアカウントを入力し、サインインしてください。
サインインしたら、左上の「サービス」をクリックし、開いたメニューの「Cloud9」をクリックします。

Cloud9のトップ画面に戻るので、”Create Environment”をクリックします。
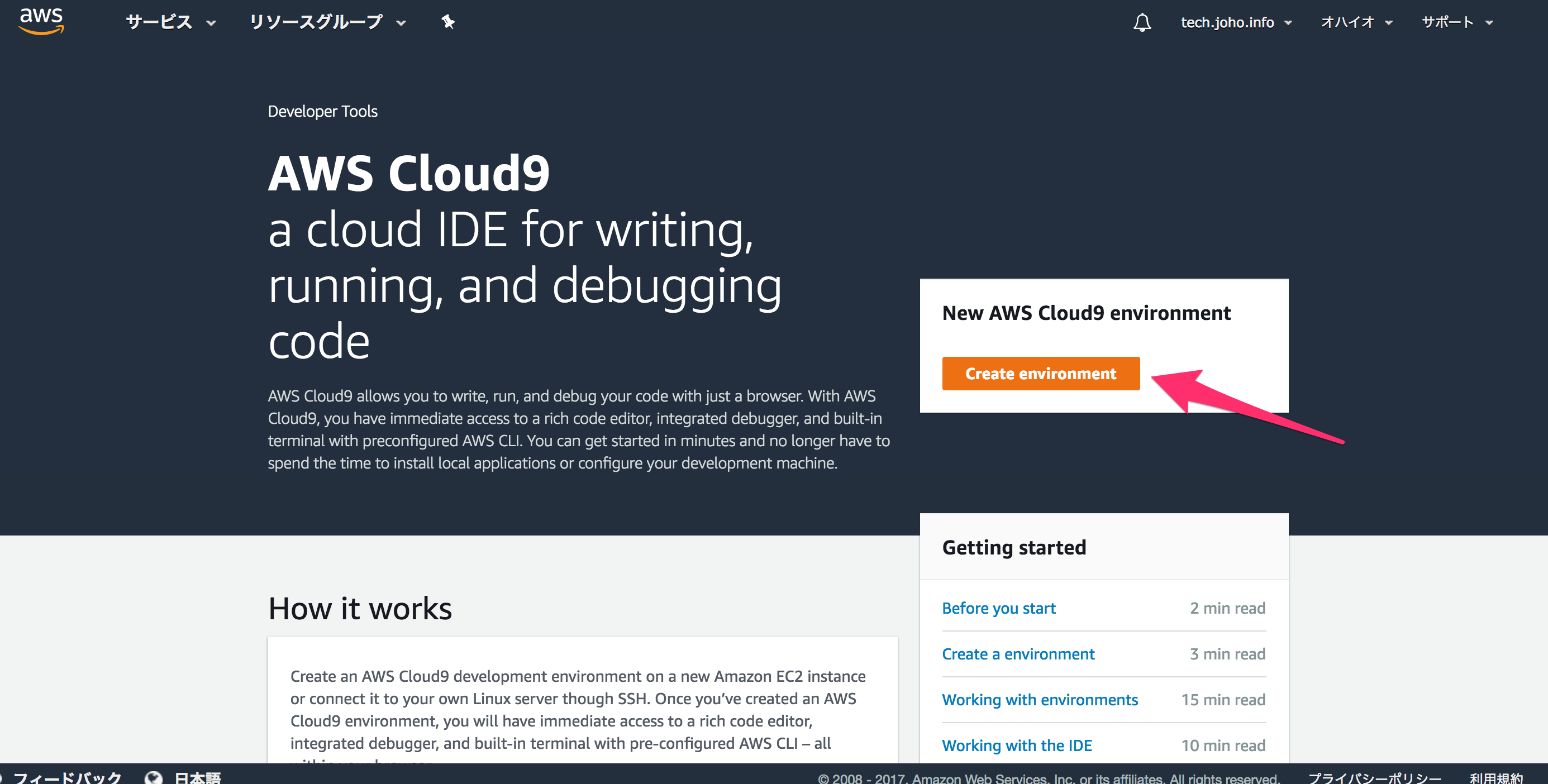
下のような画面が表示されます。
上部に表示されているアラートは、この環境専用のIAMアカウントを作れ、と言っていますが、
このアカウントで本番環境用のアプリを開発する予定がなけらばこのままでも良いでしょう。
xボタンを押して消しましょう。
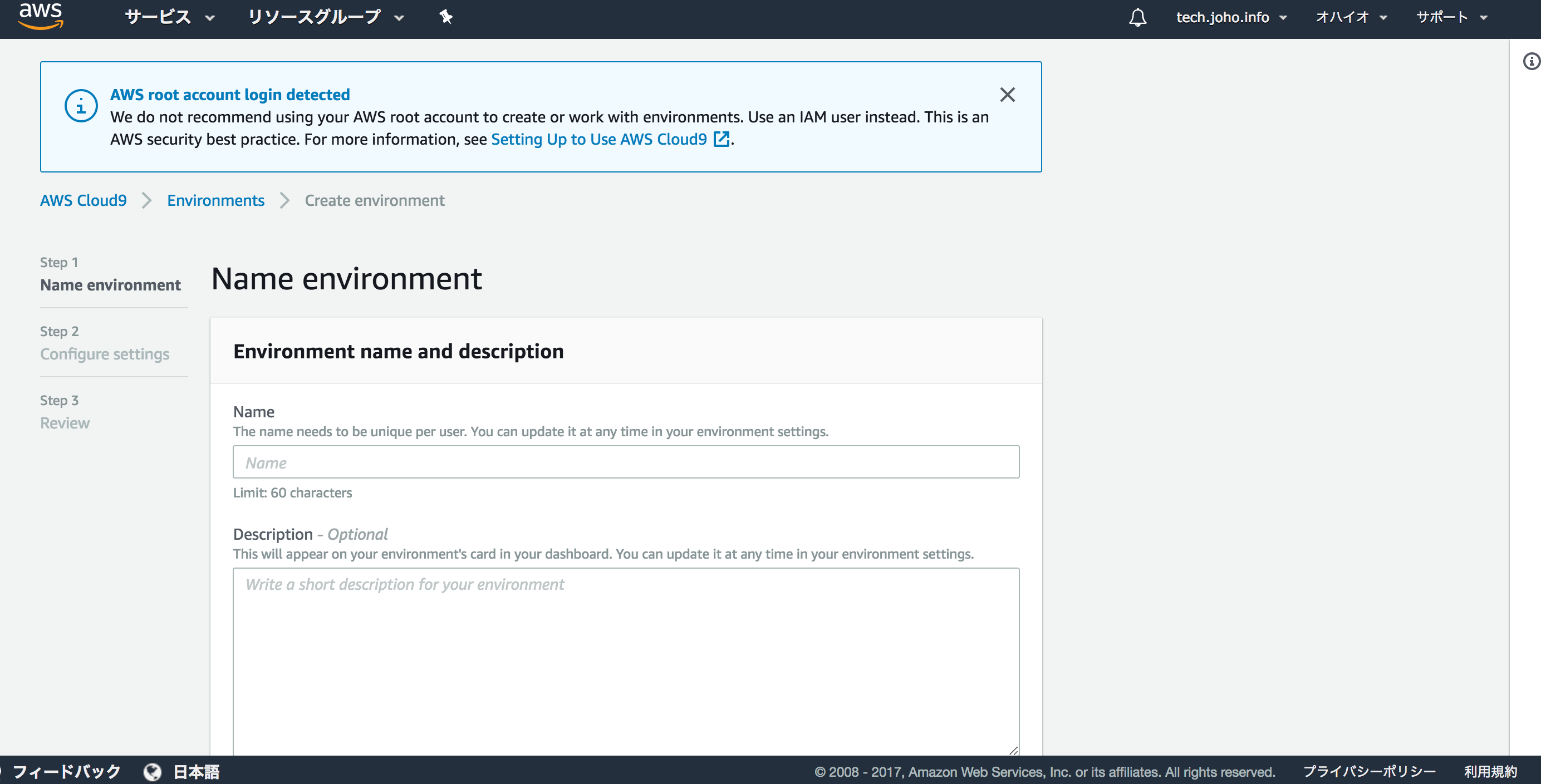
この画面では、環境の名前(Name)を入力する必要があります。
下の例では、説明(Description)も入力しています。
入力し終わったら、”Next Step”をクリックしてください。
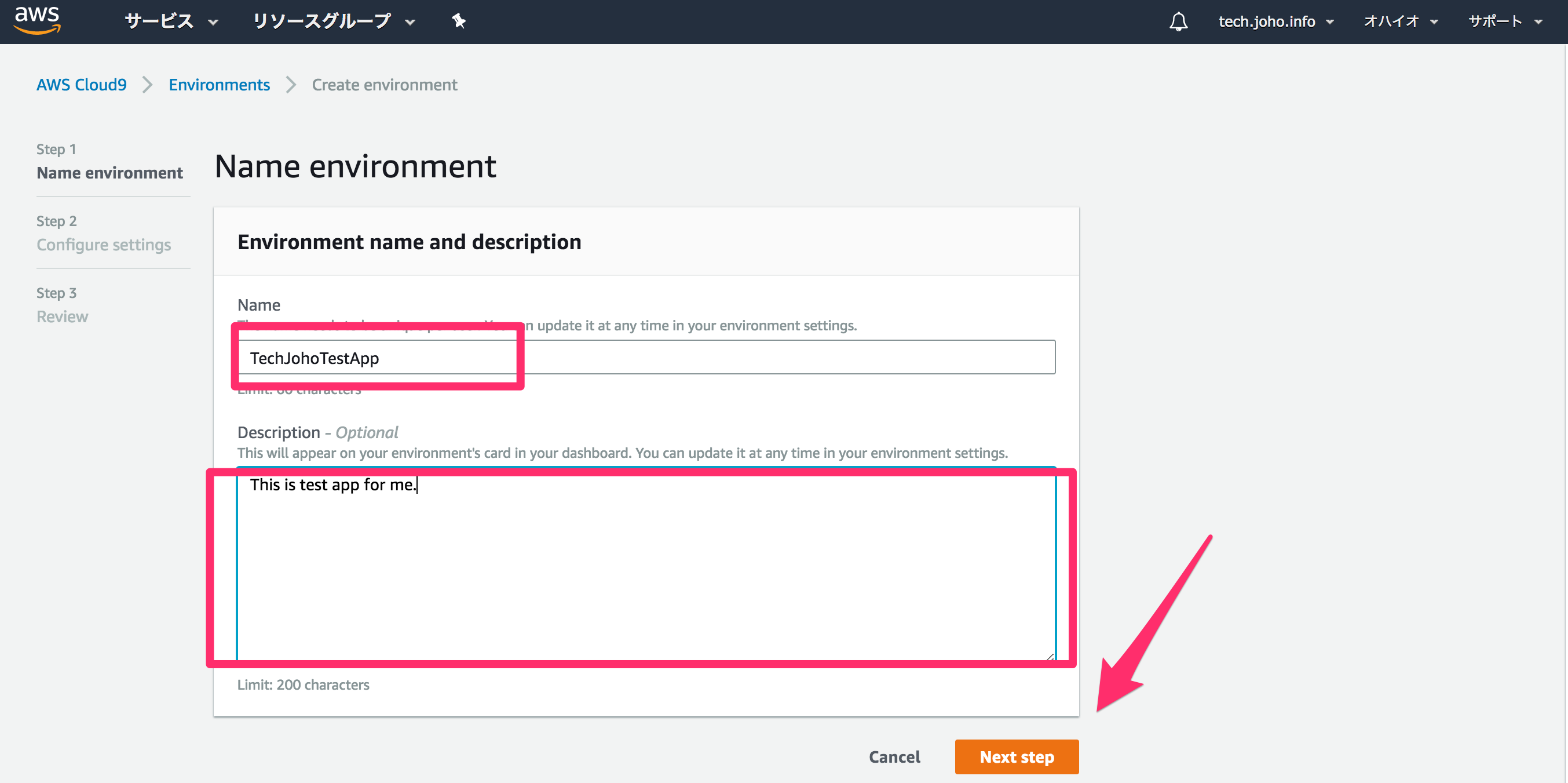
次に、Cloud9で開発する環境をどこに作るか選びます。
分かりやすいのは、初期選択の”Create a new instance for environment”です。
EC2インスタンスを新しく立ち上げます。
既存のEC2インスタンスを利用する場合はもう一つの選択肢を選びましょう。

EC2インスタンスのタイプを選びましょう。
これは仮想マシンの性能を選んでいます。
これも、開発段階なら初期選択の一番低いt2.microで十分です。
最後にまた”Next Step”をクリックします。
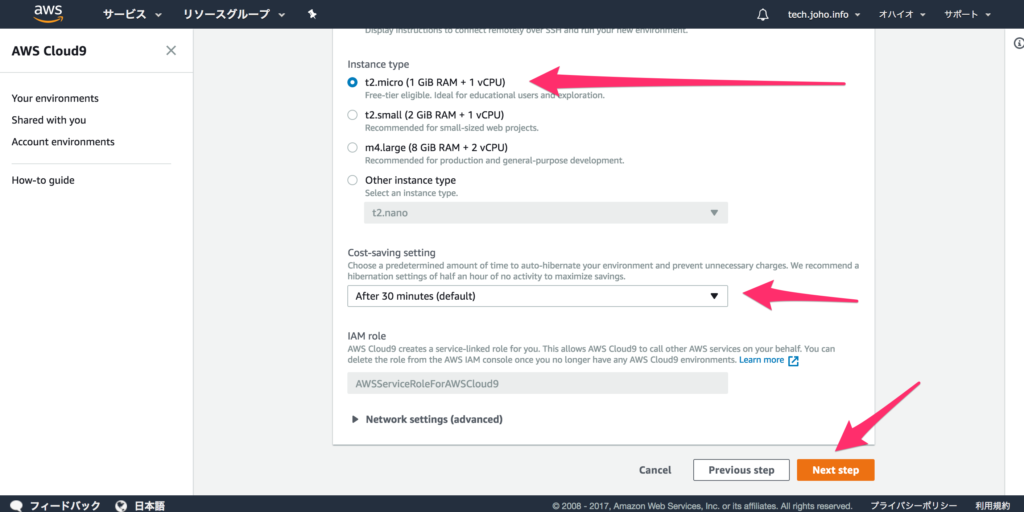
確認画面が表示されるので、これでよければ、一番下の”Create Environment”をクリックして下さい。
くるくるまわるインジゲータが表示され、2、3分待つと、環境が作成され、この環境専用のEC2インスタンスも作成されています。
Cloud9のIDE
IDEがやっと表示されました。
この画面下部は、作成したEC2インスタンスにsshログインした状態のコンソールです。
左にファイルの一覧があります。
上部にはいろいろなメニューが並んでいますが、とりあえず大事なのは”Run”ボタンくらいです。
まずは、IDEの使い方になれるために、簡単なプログラムを実行してみましょう。
真ん中にある”Create File”をクリックしてましょう。
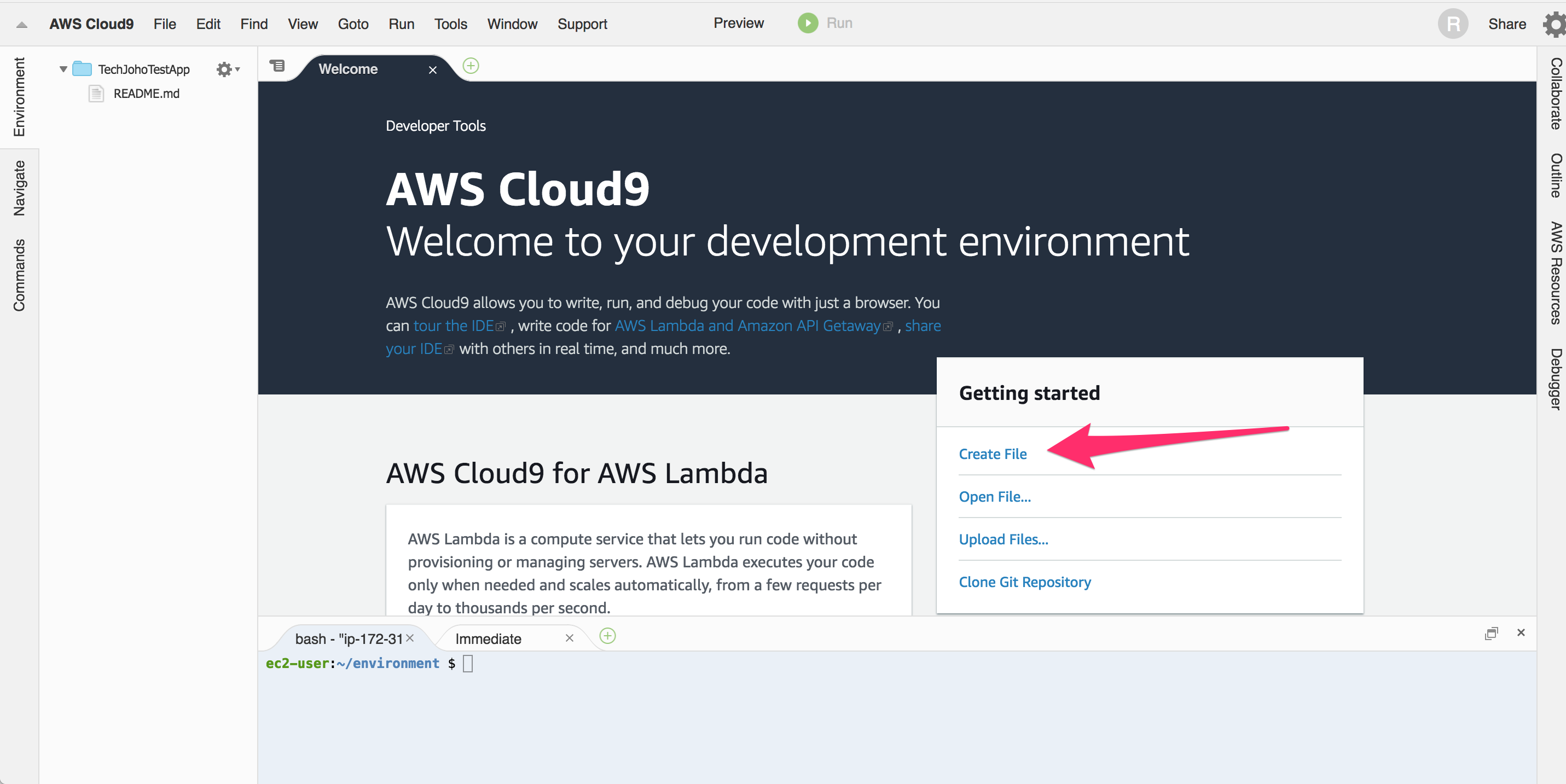
ファイルを編集するタブが開きます。タブ名は”Untitled”になっています。
まず、Pythonの簡単なFor文を書いてみます。
(ちなみに、下のコンソールでは試しにlsコマンドやvimの起動をしてみました。気になる人は試してみて下さい。)
この状態で、一旦保存しましょう。Ctrl+Sを押して下さい。
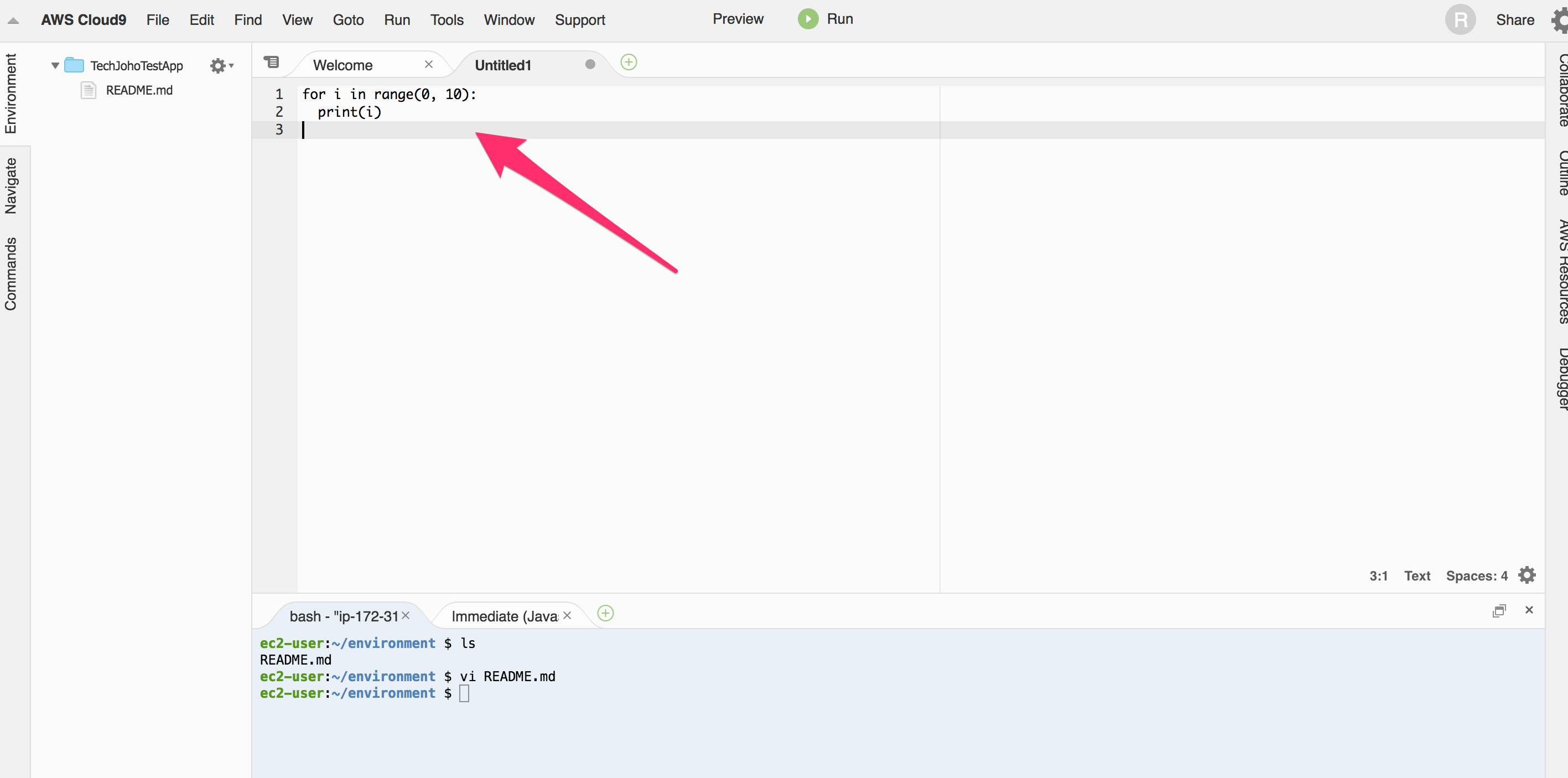
このような、保存先、保存名などをきめるダイアログが開きます。適当に入力して”Save”をクリックしましょう。
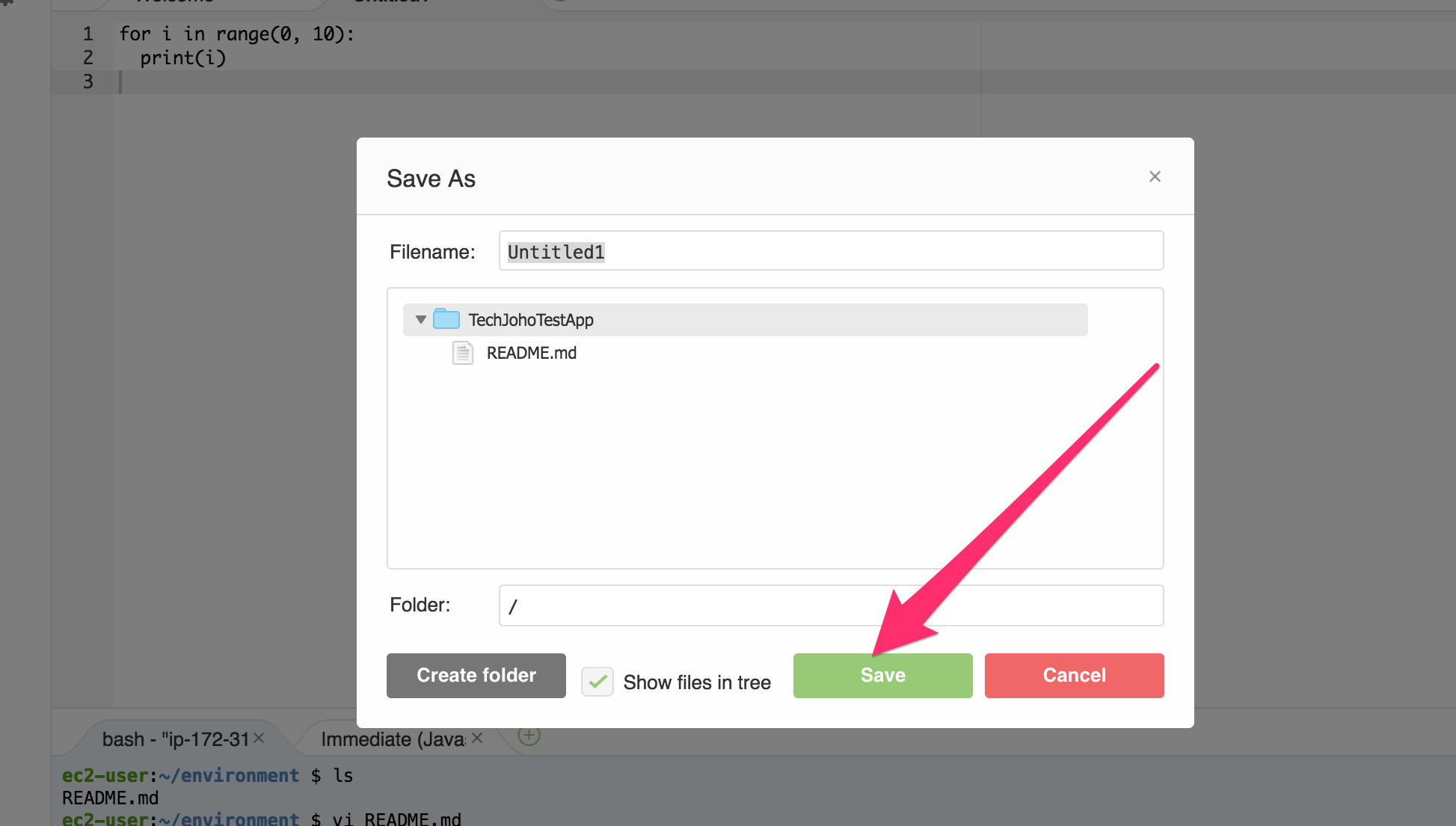
ファイルのタブにファイル名が付きました。
次に、プログラムを実行してみましょう。
上の”Run”ボタンをクリックしましょう。
下のコンソールに実行結果が表示されました。
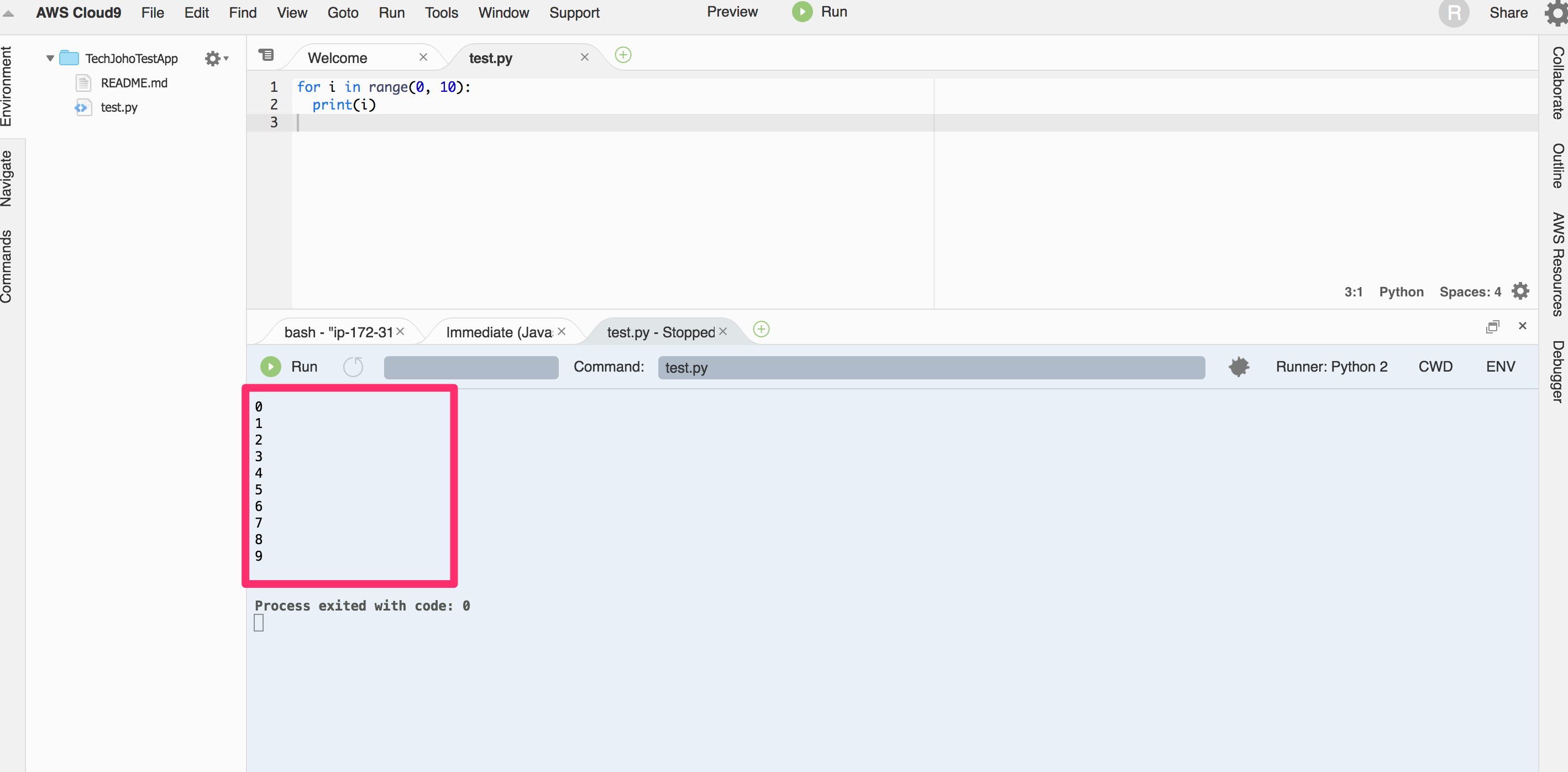
ちなみに、ファイルの編集タブの左の数字の左をクリックすると、プログラムの実行を停止するためのBreakpointを設定できます。Breakpointを設定した状態でRunすると、その箇所でプログラムを停止できます。(そのはずですが、2017年12月3日現在、うまくうごきませんでした… 早く解消されることを望みます)
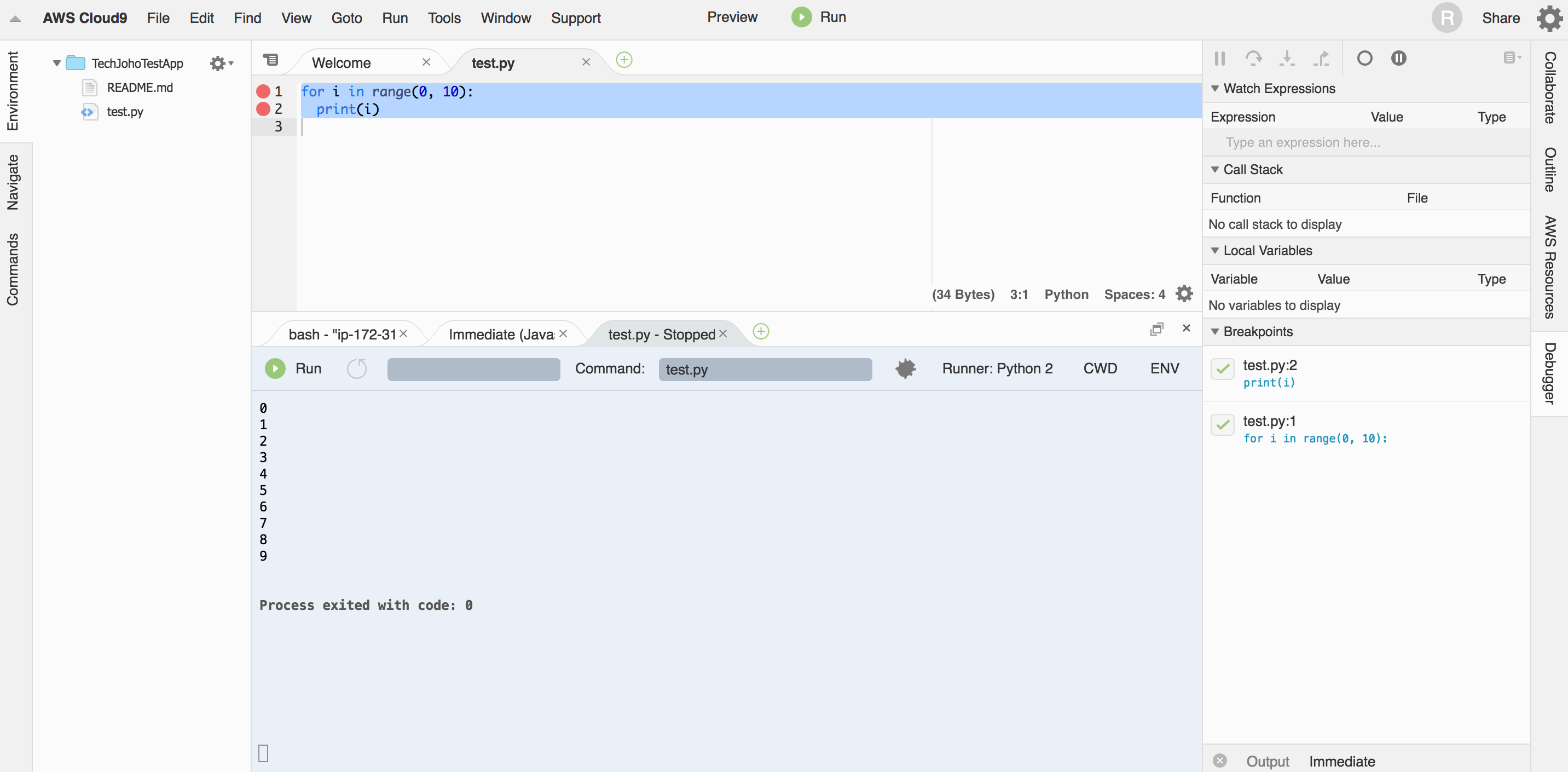
一応Pythonプログラムを作成して実行できたので、次はDjangoアプリを作ってみましょう。
Djangoアプリの起動
記事が長くなったので、Djangoアプリの作成と起動は別記事にわけたいと思います。こちらをごらんください。
AWS Cloud9でDjangoアプリを作成| Django 入門
Windows 10 condaによる環境構築からdjangoのインストール | Django 入門
Python独学ならTech-Joho TOP > django入門 > Windows 10 condaによる環境構築からdjangoのインストール
condaによるdjnagoのインストール
以前、こちらのページでvirtualenvによるdjangoのインストールから起動までの記事を公開しました。
virtualenvでWindows10 に Django インストール
しかし、condaのほうがいろいろと楽そうだったので、miniconda版のインストール手順を公開します。
minicondaのインストール
まず、minicondaをインストールします。
minicondaはpythonのデータ分析用のいろいろ便利なパッケージが入ったanadondaの最小構成版といったような存在で、djangoの開発環境としてはちょうどいいと思います。
くわしくは、下の記事をご覧ください。
minicondaは下記の公式ページからインストーラをダウンロードし、実行、次々とボタンを押していけばすぐに完了です。
minicondaダウンロードページ
https://conda.io/miniconda.html
ほとんどのばあい、64ビット版で問題ないと思います。
「64-bit (exe installer)」をクリックしてダウンロードしてください。
condaの仮想環境作成
こちらのページに全部書いてあるので実行してください..
Pythonのインストール方法の選択肢
一応、こちらには最小限の手順だけ書いておくことにします。
下の<仮想環境の名前>というところには好きな英数字の名前を入れてください。”djangoproj1″とか、”myapp”とか何でもいいです。
- インストールされた、Anaconda prompotを起動する
- Anaconda prompotで ”conda create -n <仮想環境の名前>”を実行し、仮想環境を作る
- Anaconda prompot で “activate <仮想環境の名前>”を実行し、仮想環境を有効化する
- いろいろ作業する
一応、ここでは”djangoapp1″にしたことにして説明を続けます。。
> conda create -n djangoapp1
途中で”Proceed ([y]/n)? y”と聞かれるのでy、エンターを押します。
condaによるdjangoのインストール
Anaconda promptを起動し、djangoアプリを作る仮想環境を有効化します。
ここでは、上記で作成したdjangoapp1を有効化します。
> activate djangapp1
有効化されると、下のように、プロンプトの左側に仮想環境名が表示されます
(djangoapp1) >
この状態で、下のコマンドを実行して、djangoをインストールしましょう
(djangoapp1) > conda install django
途中で”Proceed ([y]/n)? y”と聞かれるのでy、エンターを押します。
こんな風に、condaコマンドはpipの代わりのように使えます。
djangoのプロジェクト作成
まず、cdコマンドでプロジェクトを作りたいフォルダまで移動します。
ここでは、ユーザのHOMEPATHの下にprojectsフォルダを作りそこに移動します。
(djangoapp1) > mkdir projects (djangoapp1) > cd projects
プロジェクトを作るには、以下のコマンドを実行します。
(djangoapp1) >django-admin startproject <プロジェクトの名前>
先ほどと同じように、<プロジェクトの名前>は自由です。
ここでは、djangoproject1という名前にすることにして進めます。
(djangoapp1) >django-admin startproject djangoproject1
これで、自動的にプロジェクト名を同じ名前のフォルダが作成され、中にdjangoのプロジェクトに必要なファイルが自動でコピーされました。
プロジェクトのフォルダに移動し、djangoのアプリサーバを起動してみましょう。
(djangoapp1) > cd djangoproject1 (djangoapp1) > python manage.py runserver
anaconda prompotは大体このようになっているはずです。
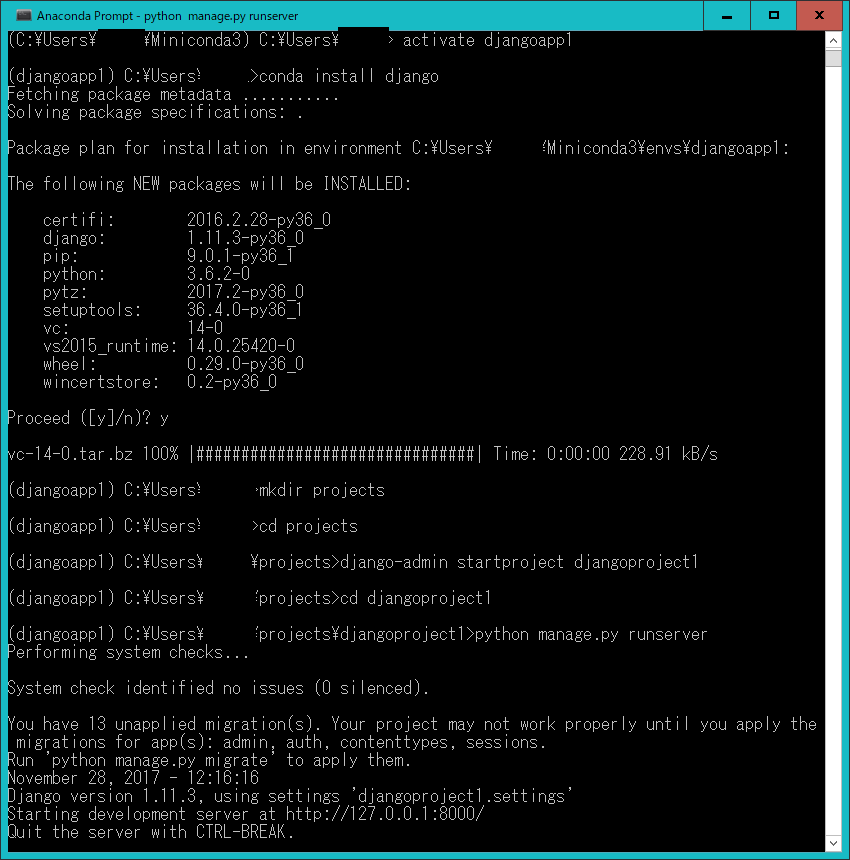
最後に、http://localhost:8000/にブラウザでアクセスして、djangoアプリの起動を確認しましょう。
このように表示されていれば成功です。
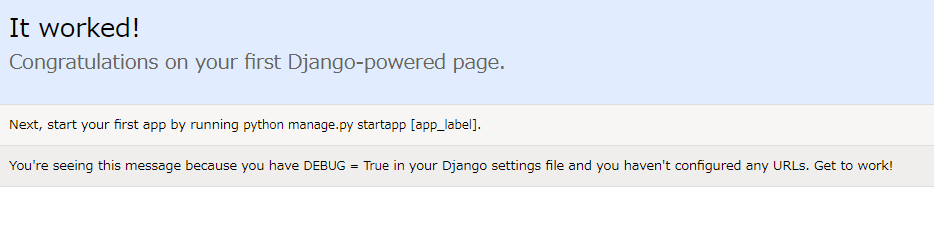
ただし、このままではプロジェクトは空っぽですので、これから内容を開発していく必要があります。
これからの手順についてはこちらをご覧ください。
Pythonのインストール方法の選択肢 | Django 入門
Python独学ならTech-Joho TOP > django入門 > Pythonのインストール方法の選択肢
どれを選べばいいか
Windows10でDjangoの開発をするにあたって、そもそもPythonをインストールする方法が複数あります。
どれを選べばいいか、一つ一つメリット・デメリットを考えてみます。
主な方法は3つあります。
結論から言うと、anacondaを使うのが特に初心者には無難な気がします。
(が全く面倒がないわけではありません…)
参考
データサイエンティストを目指す人のpython環境構築 2016
https://qiita.com/y__sama/items/5b62d31cb7e6ed50f02c
Windows版インストーラ
Windows版インストーラのダウンロード
インストーラは下のリンク先からダウンロードできます。
python.org(Pythonの公式ページ)
https://www.python.org/downloads/
「Download Python 3.6.3」をクリックして下さい。
Windows版インストーラによるインストール
インストーラをダブルクリックして起動後、「Install Now」をクリックしてください。
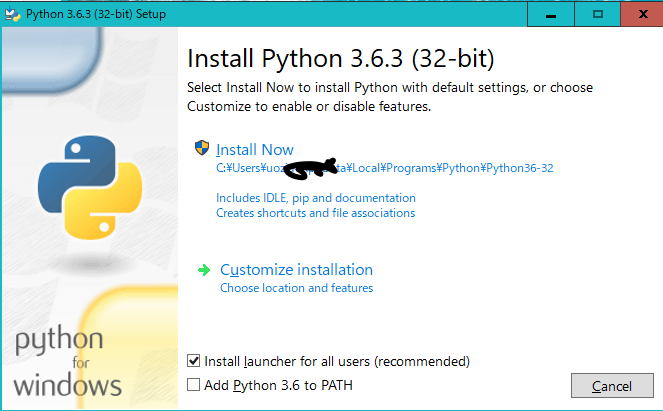
ウインドウの下にある「Add Python 3.6 to PATH」というチェックボックスは、Pythonの実行ファイルまでのPathを環境変数に追加するか否かを選択するものです。
ここで、ほかにPythonを使う予定がある場合、追加してしまうと、今インストールしているPythonが優先になってしまいます。どうすべきかは状況によります。
このような判断も、仮想環境を使うと必要がなくなるので、インストーラを使う方法は実はおすすめでははありません。
この記事ではチェックを入れないで進むことにします。
また、この手順でインストールされるのは、Pythonの32ビット版です。
「Setup was successful」という画面が表示されたら正常にインストールが完了しています。
Windows版インストーラでインストールしたPythonを使う方法
スタートメニューに「IDLE(Python 3.6 32-bit)」が追加されているはずです。
こちらをクリックすると、Pythonと同時にインストールされた簡易的な統合開発環境IDLEが起動します。
こちらには、Pythonを対話的に実行できる、つまりコードを入力してすぐ結果を見ることのできる環境Python 3.6.2 Shellと、ファイルにPythonコードを書いて実行できる機能が含まれています。
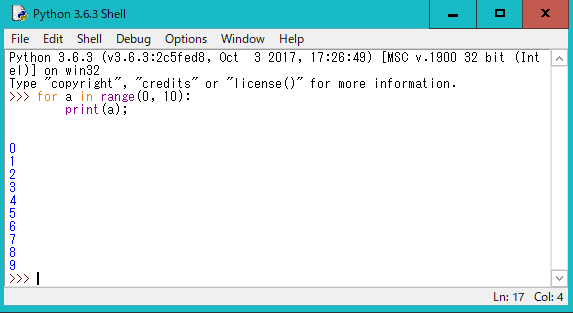
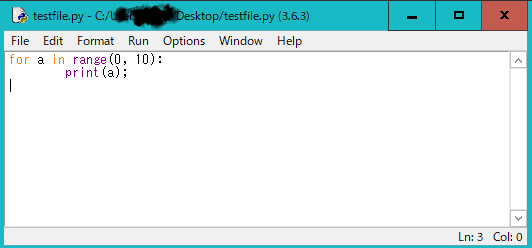
Pythonの学習時などに、ちょっと実行してみたいときはShellを、プログラムを開発するときにはファイルの編集機能を使いましょう。
IDLEのファイルの編集画面では、「F5」キーを押すことですぐに実行できて便利です。
プログラムを実行した結果は、このようにShellに表示されます。
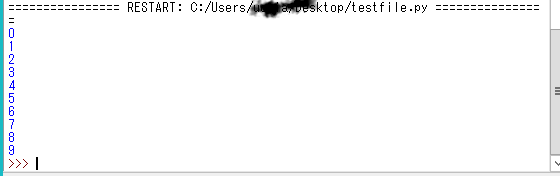
*また、もし、インストール時に「Add Python 3.6 to PATH」にチェックを入れていた場合、PowerShellを起動してPythonと入力し、エンターキーを押すとインストールしたPythonが実行されます。
Windows版インストーラで入れたPythonのメリットとデメリット
メリットとして考えられるのはインストールが簡単なことです。
デメリットは複数のPythonをインストールしなければならない状況に対応しずらいことです。
PythonやDjango本体を含めたPythonのパッケージは、日々更新されていきますが、それぞれが特定のバージョンに依存しています。
あるアプリを開発した古いPythonの環境を残したまま、別のアプリを新しい環境で構築したい、ということはよくありますが、この方法だけでは対応できません。
また、既にシステムに古いPythonが入っていて、それに依存するソフトウェアがある場合、そのソフトウェアが動かなくなるなどの問題が発生する可能性もあります。
デメリットが大きいので、このPythonをそのまま使用するのは基本的におすすめの方法ではありません。
venv
venvはPython3.6に付属の仮想環境管理ツールです。
異なるパッケージのインストールされた仮想環境を複数作ることができます。
venvによる仮想環境の作成方法
Windows PowerShellを開いて、下記を実行します。
> python3 -m venv <仮想環境のパス>
簡単です。
一つ注意点は、venvを利用するには、上記の公式のインストーラでPythonをインストールしておかないといけないということです。
また、異なるバージョンのPythonを利用する方法は私はわかりませんでした…
(virtualenvという非常に普及している別のツールならできます)
参考
28.3. venv — 仮想環境の作成(Pythonの公式ドキュメント)
https://docs.python.jp/3/library/venv.html
venvで作った仮想環境の利用方法
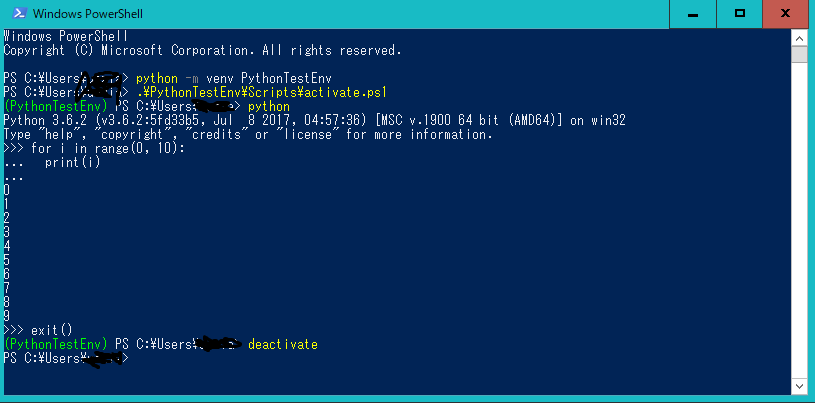
まず、仮想環境をactivate(有効化)します。
> <仮想環境のパス>/bin/activate
この環境でインストールしたパッケージ等は、外の世界のPythonに影響を与えません。
仮想環境から出るにはdeactivateです。
deactivate
実行してみた例です。
venvメリットとデメリット
venvによって作った仮想環境のPythonを利用するメリットは、インストールしたパッケージが、外の世界のPythonに影響を与えないことです。
開発するアプリケーションごとに仮想環境を作れば、お互いに影響を与えずに開発を進めることができます。
あるアプリで、あるパッケージのバージョンを上げたことで別のアプリが動かなくなる、という事態を防ぐことができます。
デメリットは、最初のPythonは、インストーラで導入する必要がある点です。
Anaconda
AnacondaはPython開発環境が簡単を作ることのできる便利ツール、と私は理解しています。
公式ページのWhat is Anaconda?では、「世界で一番人気のデータサイエンスの基盤」と書いてあるように、Anacondaには、データ解析に便利なツールがたくさん含まれています。
例えばPythonコードを埋め込めるノートアプリJupyter Notebookなどです。
Anaconda公式ページ
https://www.anaconda.com/
ただ、Anacondaはそれ以外にもいろいろな機能があり、仮想環境をつくることもできます。
また、pipの代わりになるパッケージマネージャとしての機能もあります。(pipを併用することも可能)
ただし、いろいろなパッケージを含んでいてとても容量が大きく、インストールも大変で、Djangoの開発環境として要らない機能も多いので、
私は最小構成版のminiconaをおすすめします。
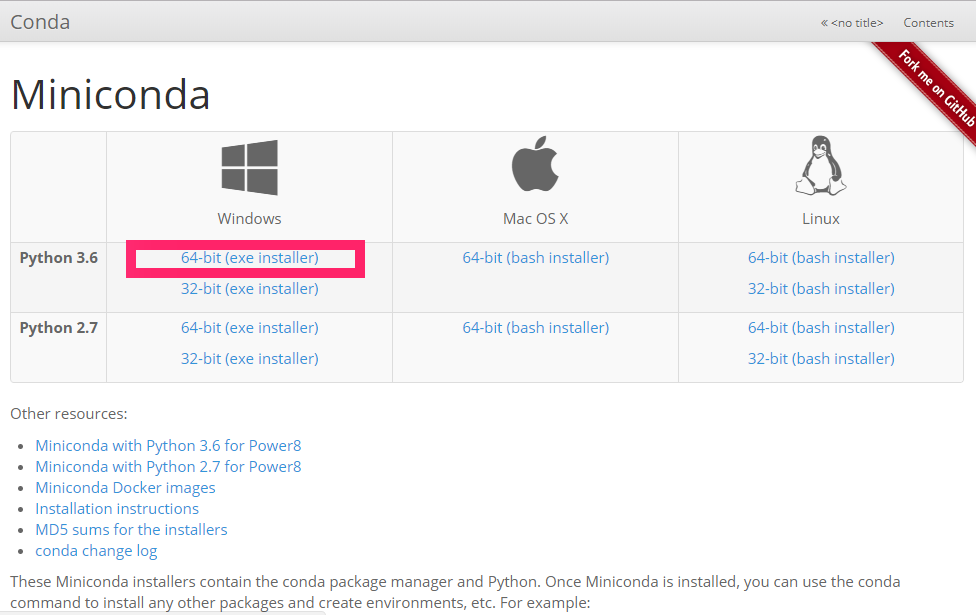
minicondaのダウンロード
minicondaダウンロードページ
https://conda.io/miniconda.html
上記のページからインストーラをダウンロードしましょう。「64-bit (exe installer)」をクリックしてください。
minidondaのインストール
ダウンロードしたインストーラをダブルクリックして起動し、基本的に「next」等を押していけば完了します。
minidondaの使い方
インストールが完了したら、スタートメニューに「Anaconda Prompt」が追加されているはずです。

クリックして起動しましょう。
基本的にこのAnaconda promptを使ってPythonを実行しましょう。
ここでのPythonの使い方は、venvと似ています。
Anacondaの仮想環境の作成方法
Anaconda promptで、仮想環境をつくりましょう
> conda create -n <仮想環境の名前>
途中で、「Proceed ([y]/n)?」と聞かれるので、yを押しましょう。
簡単です。
Anacondaの仮想環境の利用方法
Anaconda promptで、以下を実行すると、仮想環境に入ることができます。
> activate <仮想環境の名前>
仮想環境からでるにはdeactivateです。
> dactivate
一通り実行してみました。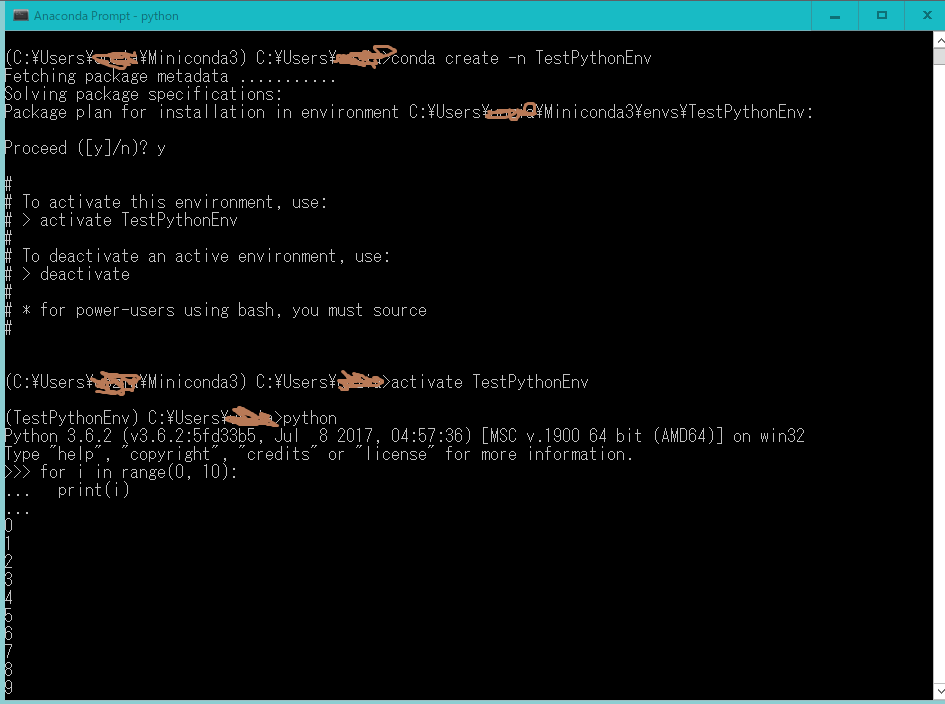
Anacondaのメリットとデメリット
Anacondaのメリットは、venvのメリットがすべてに加えて、最初にPythonをインストールしなくてもよいところです!
あと、仮想環境ではpython自体のバージョンも変えることができます。
デメリットとしては、Djangoアプリケーション開発環境としてはいらないもの(Jupyter notebookなど)が入ってしまう点でしょうか。
ただ、全体としてはAnacondaが一番すっきりした環境だと感じます。
結論
というわけで、3つの環境を見た結果、Anaconda promptが一番のような気がします。