Python独学ならTech-Joho TOP > いろいろやってみた >PythonスクレイピングツールScrapyで定期的に情報取得
PythonでWebサイトに書いてある情報を取得する
プログラムを使って、Webサイトに書いてある情報を取得することがスクレイピングです。
いわゆるクローリングにも近い概念です。
Pythonで実施することができ、その方法も色々ありますが、お手軽なのがScrapyというツールを使うことです。
Scrapy公式ページ
https://scrapy.org/
インストールするには、pipで以下のように実行します。
> pip install Scrapy
Scrapyの基本的な使い方
Scrapyのいちばん大事なWebページにアクセスして書いてある内容を読み取る機能は、SpiderというPythonのクラスに集約されています。
これを継承したオリジナルのクラスを作成するのが、Scrapyを使う最初の一歩です。
例えば、Yahoo! Japanのニュースのページにアクセスして、一番上のニュース欄にある見出しを取得・表示してみます。
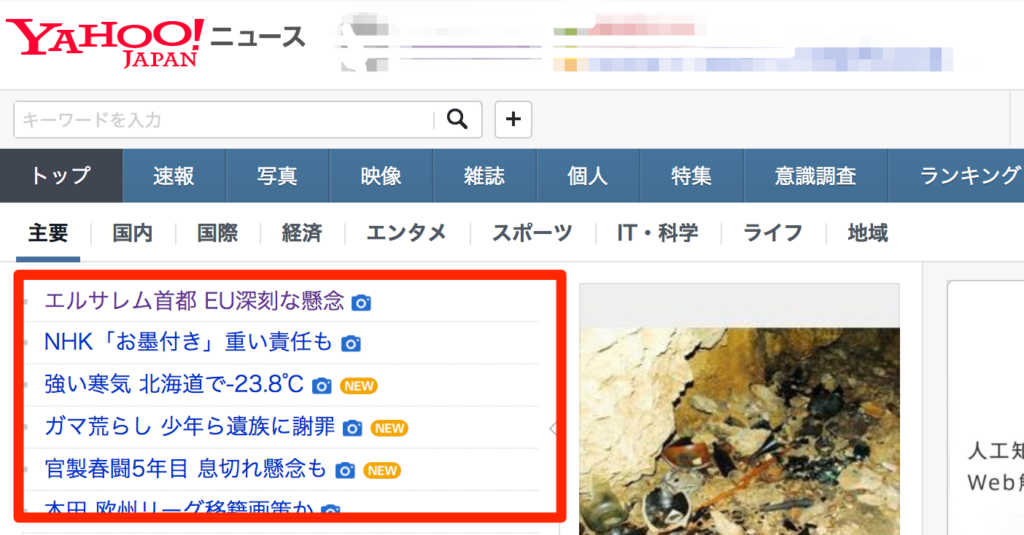
以下のようなファイル yahoospider.py を作成します。
yahoospider.py
import scrapy
class YahooSpider(scrapy.Spider):
name = 'yahoospider'
start_urls = ['https://news.yahoo.co.jp/']
def parse(self, response):
print("start")
for title in response.css(".topics .ttl a::text"):
print(title.extract())
ポイントは parseメソッドで、response.css()をつかって、CSSセレクターでニュースのタイトルの要素を探しています。
“.topics .ttl a::text”というCSSセレクターは、topicsクラスを持つ要素の下のttlクラスを持つ要素の下のa要素のテキストすべて、という意味です。
これを実行するには、コマンドプロンプトなどで以下のコマンドを実行します。
> scrapy runspider yahoospider.py
たくさん文字が表示されますが、中程にニュースタイトルがでてくるはずです。
略 2017-12-07 09:22:59 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) start エルサレム首都 EU深刻な懸念 NHK「お墨付き」重い責任も 強い寒気 北海道で-23.8℃ ガマ荒らし 少年ら遺族に謝罪 官製春闘5年目 息切れ懸念も 本田 欧州リーグ移籍画策か 宇野余裕 寝坊も寝癖もなんの 瀬戸康史 美しい女装男子役 略
Scrapyの機能はたくさんあるのですが、基本的にはこれで十分ではないでしょうか?
繰り返し実行してみた
1分毎や1時間ごとなど、あるサイトに定期的にアクセスして情報の変化を追いたい事があると思います。
これもいろいろな方法がありますが、素朴な方法として、上記のコマンドをタイマーを仕込んだpython経由で実行する方法を書いてみました。
repeat.py
from subprocess import call
import os
import time
dir_path = os.path.dirname(os.path.realpath(__file__))
os.chdir(dir_path)
while True:
call(["scrapy", "runspider", "yahoospider.py"], cwd=dir_path)
print('run spider')
time.sleep(30)
下記のコマンド実行で、30秒に1回、yahooニュースの情報を取得します。
> python repeat.py
上のコードはこちらからダウンロードできます。
https://github.com/tech-joho-info/scrapy-sample-news-site
上のプログラムを改造すれば、いろいろなサイトに応用できます。
是非試してみて下さい。
ただし、あまり頻繁にアクセスするとサイバー攻撃になってしまいますので、気をつけて下さい。