KerasとCloud9
この記事では、Cloud9で作ったEC2環境に上にKerasをインストールしてディープラーニングを試してみます。
Windowsを使っている等、自分のPCにいろいろインストールしたくない人はこの方法がおすすめです。
(べつにWindowsでもできますが)
Kerasは深層学習用のライブラリの一つです。
他に有名なのはgoogleのTensorflowですが、Kerasは、他にもいろいろあるライブラリを上から使う上位のライブラリという感じです。
この記事でも実際の計算はTensorflowにやらせていますが、Kerasを間にかませることでコードが簡単になります。
機械学習自体の研究者ならともかく、結果を利用するだけなら、Kerasでいいのではないでしょうか。
Cloud9は、Webブラウザ上で使用できるIDE(統合開発環境)ですが、Amazonに買収されAWSのサービスと統合されたので使いやすくなり(?)、注目されています。
詳しくは下の記事をご覧ください。
AWS Cloud9でPython開発する準備
環境の構築
まず、仮想環境を構築します。
この記事のとおりに実行してください。
AWS Cloud9でPython開発する準備
pythonも3に設定します。
また、EC2のIPアドレスをメモしておきましょう。jupyter notebookにアクセスするのに必要です。
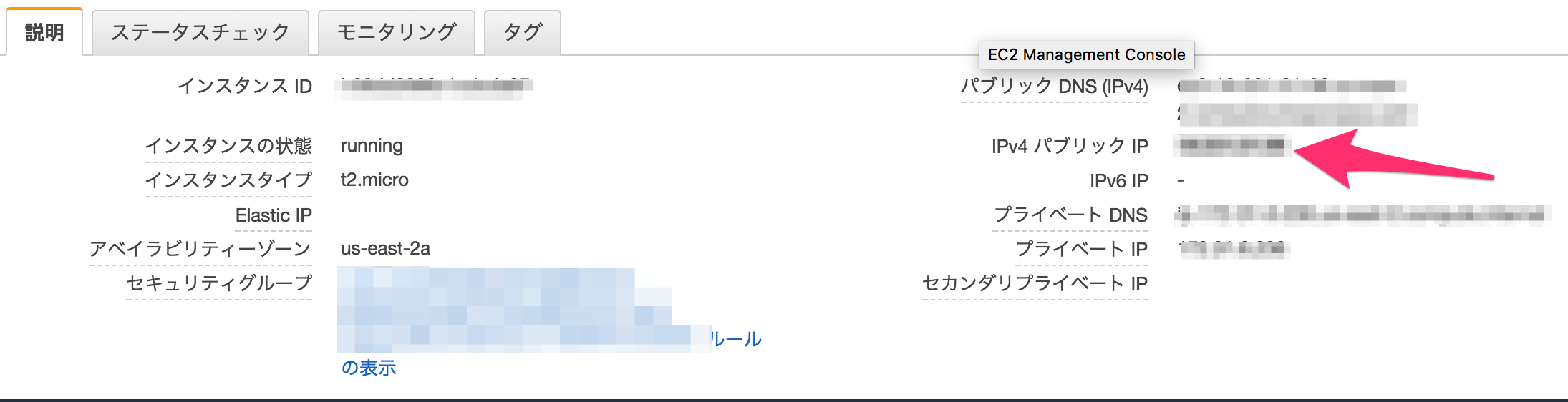
セキュリティ設定
また、Jupyter notebookを使うために、80ではなく8888ポートを開けて置きましょう。
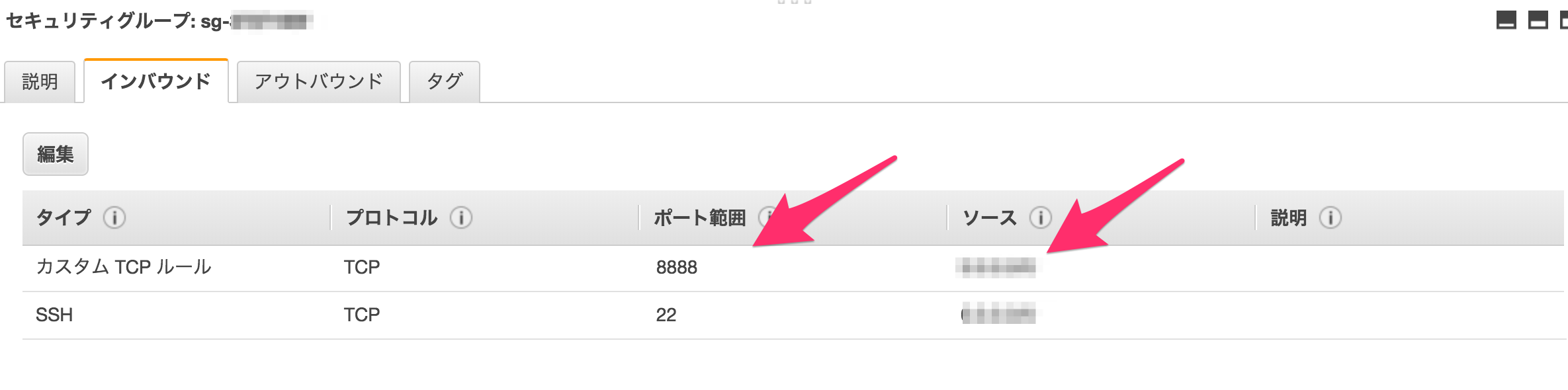
また、他の人のアクセスを防ぐために、パスワード認証をしたり、IPアドレスでアクセス制限をかけましょう。
方法は、下のサイトに詳しいです。
Jupyterをサーバ上で起動する
http://www.mwsoft.jp/programming/numpy/jupyter.html
Jupyter notebookのパスワード
https://qiita.com/SaitoTsutomu/items/aee41edf1a990cad5be6
インストール
tensorflow、keras、jupyternotebookをインストールします。
cloud9のEC2のコンソールで以下を実行します。
$ sudo pip-3.6 install -U tensorflow $ sudo pip-3.6 install -U keras $ sudo pip-3.6 install -U pillow $ sudo pip-3.6 install -U matplotlib $ sudo pip-3.6 install -U jupyter
こんな感じに、画面下のところに入力してコマンドを実行します。

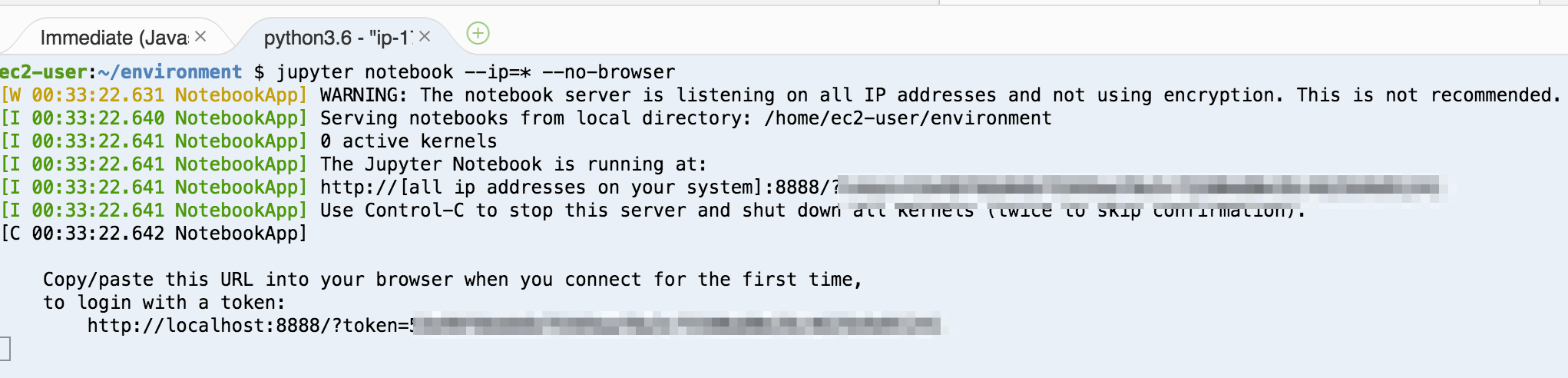
次に、jupyter notebookを起動しましょう。下のコマンドを実行します。
$ jupyter notebook --ip=* --no-browser
こんな感じになれば、jupyterの起動に成功しています。
この時、「token=」の後ろにあるトークンをメモしておきましょう。jupyter notebookのログインに必要です。
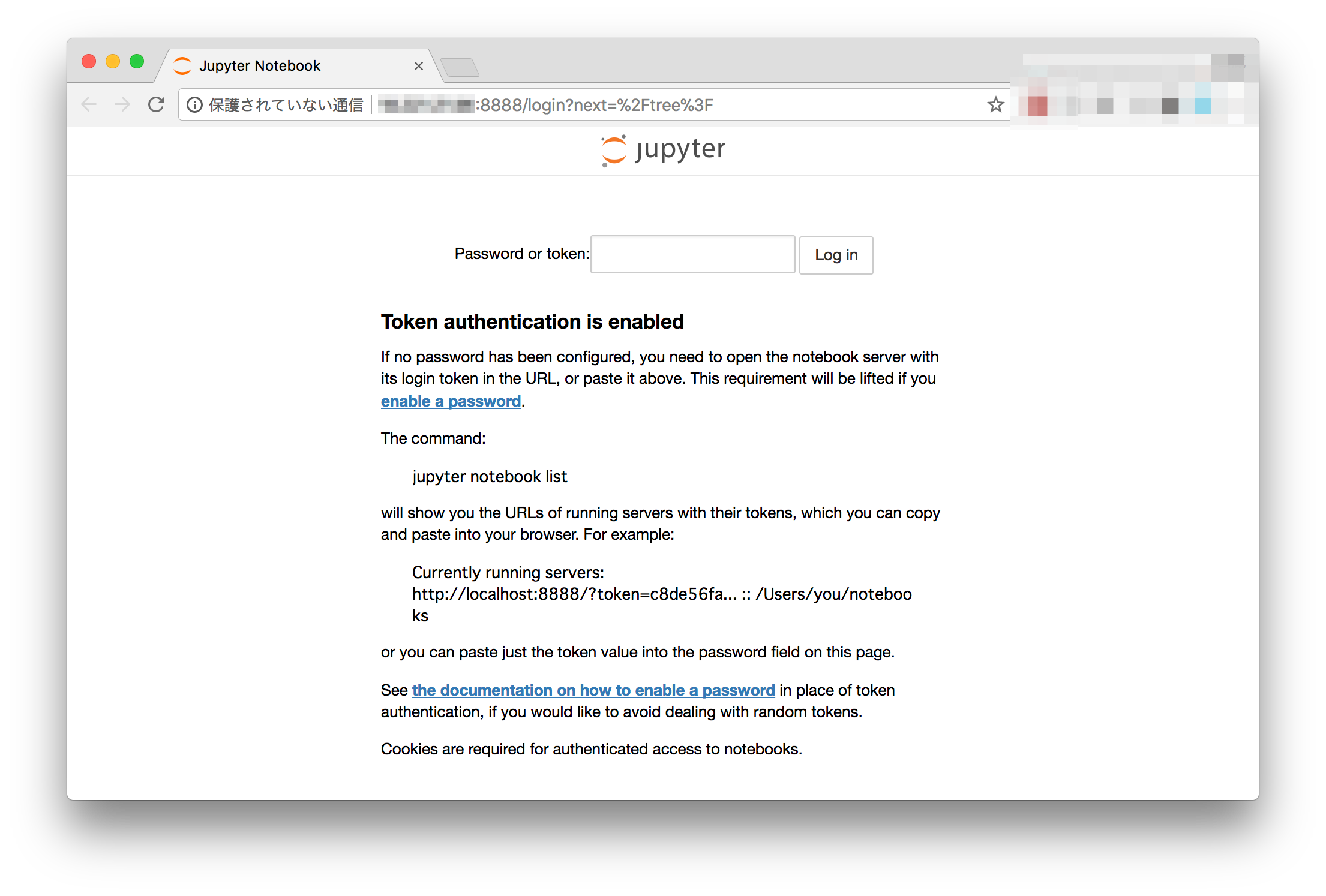
最初にメモしたEC2のIPアドレスの後ろに:8888をつけてブラウザでアクセスすると、下のようなページが開くはずです。
“Password or token”の欄に先程メモしたトークンを入力するとログインできます。
右上にあるNewをクリックし、次にPython3をクリックします。新しいノートが作られます。
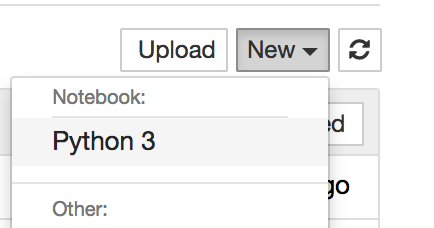
こんな感じです。これで準備完了です。では、 kerasを動かしてみましょう。

最低限のネットワークを動かしてみる
Developpers.IOにのっている、最低限のネットワークを動かしてみましょう。
下のコードをコピーしてノートに貼り付け「Shift+スペース」を押して実行しましょう。
引用元: https://dev.classmethod.jp/machine-learning/introduction-keras-deeplearning/
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers.core import Dense, Activation
from keras.utils import np_utils# Kerasに含まれるMNISTデータの取得
# 初回はダウンロードが発生するため時間がかかる
(X_train, y_train), (X_test, y_test) = mnist.load_data()# 配列の整形と、色の範囲を0-255 -> 0-1に変換
X_train = X_train.reshape(60000, 784) / 255
X_test = X_test.reshape(10000, 784) / 255# 正解データを数値からダミー変数の形式に変換
# これは例えば0, 1, 2の3値の分類の正解ラベル5件のデータが以下のような配列になってるとして
# [0, 1, 2, 1, 0]
# 以下のような形式に変換する
# [[1, 0, 0],
# [0, 1, 0],
# [0, 0, 1],
# [0, 1, 0],
# [1, 0, 0]]
# 列方向が0, 1, 2、行方向が各データに対応し、元のデータで正解となる部分が1、それ以外が0となるように展開してる
y_train = np_utils.to_categorical(y_train)
y_test = np_utils.to_categorical(y_test)# ネットワークの定義
# 各層や活性関数に該当するレイヤを順に入れていく
# 作成したあとにmodel.add()で追加することも可能
model = Sequential([
Dense(512, input_shape=(784,)),
Activation(‘sigmoid’),
Dense(10),
Activation(‘softmax’)
])
# 損失関数、 最適化アルゴリズムなどを設定しモデルのコンパイルを行う
model.compile(loss=’categorical_crossentropy’, optimizer=’sgd’, metrics=[‘accuracy’])# 学習処理の実行
model.fit(X_train, y_train, batch_size=200, verbose=1, epochs=20, validation_split=0.1)# 予測
score = model.evaluate(X_test, y_test, verbose=1)
print(‘test accuracy : ‘, score[1])
これは、MNISTというデータベースを使い、手書き数字の画像に何の数字がかかれているか判別する判別器をつくるというコードです。
THE MNIST DATABASE of handwritten digits
http://yann.lecun.com/exdb/mnist/
こんな風に貼り付けます。

実行すると、ずらずらと数値がでてきます。学習を進めている様子が出力されています。一番下にでてきたtest accuracyが最終的な正解率です。
この例では、0.8901です。あまり良くありません。
DeepLearningやニューラルネット自体の解説は長くなるので他の記事を参考にしてください。
判別させてみよう
上の例をコピペして動かしただけでは、ディープラーニングデキた!という感じがしないと思いますので、今作ったモデルを利用して、実際に手書きで数字を書いて、何の数字が書いてあるか判別させてみましょう。
まず、ペイントなどで数字を書きます。それを、MNISTのフォーマットと同じ28×28のサイズのBMP画像として保存しましょう。
この画像ファイルをブラウザのcloud9のタブの左側、ファイルの一覧にドラッグ&ドロップでアップロードしましょう。
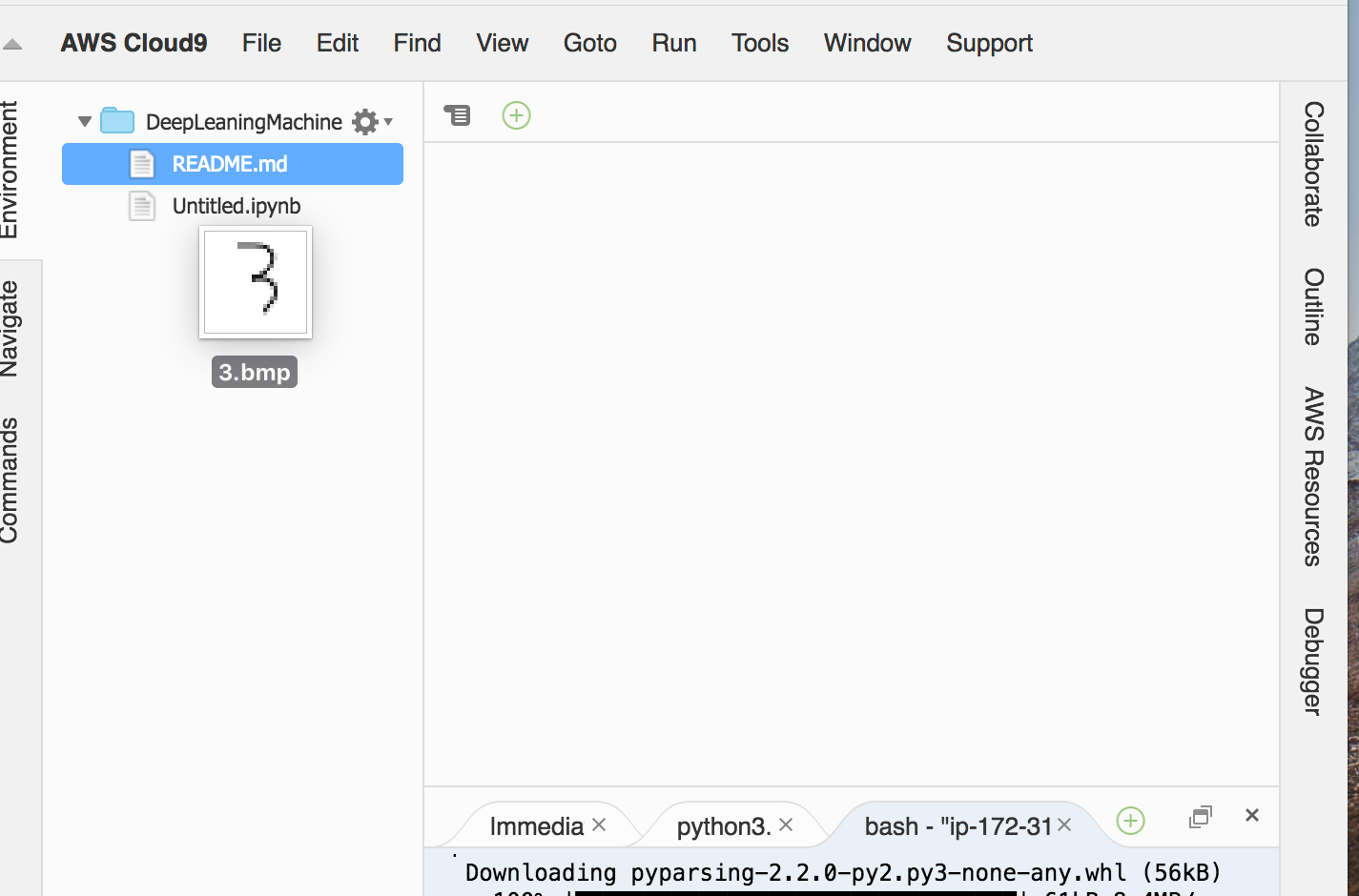
こんな風にアップロードできます。
次に、このファイルを読み込んでみましょう。
Jupyter notebookのウインドウを開き、入力欄に以下のコードを入力して「Ctrl+スペース」で実行します。
(3.bmpとなっているところにあなたがアップロードしたファイル名をいれてください。)
from PIL import Image
import matplotlib.pyplot as plt
import numpy as np
im = Image.open("./3.bmp")
image_array = np.array(im)
plt.imshow(image_array)
こんな風に表示されます。
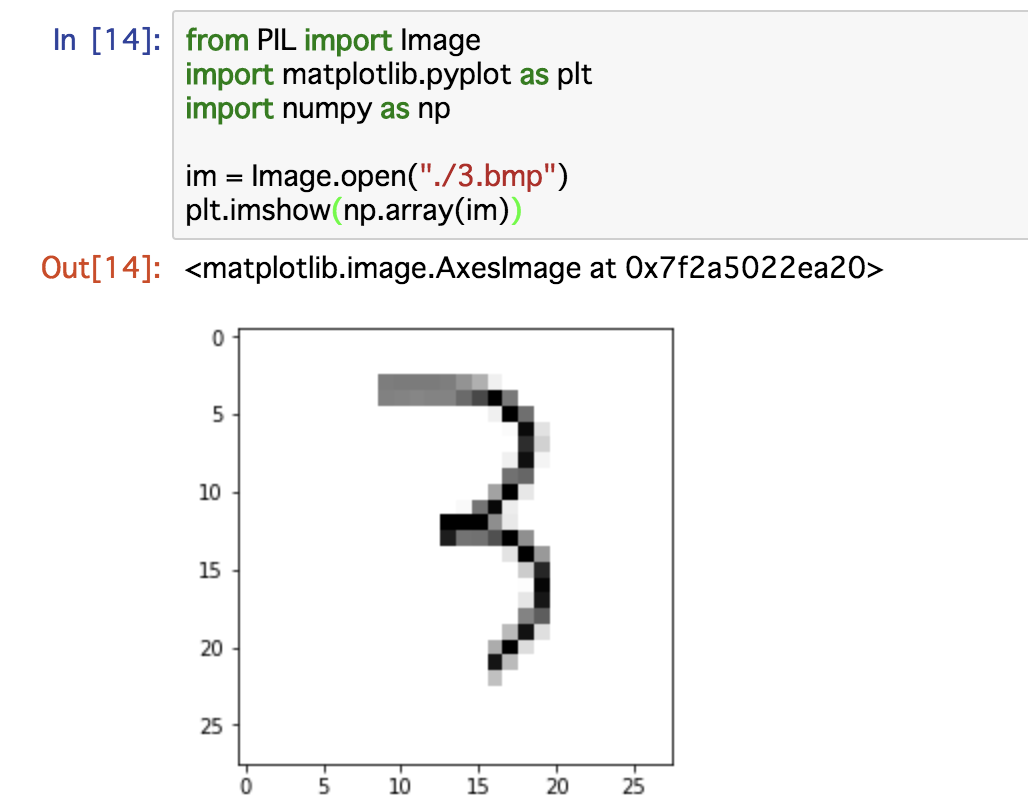
では、この手書き文字が何の数字を書いてあるのか、ニューラルネットに予測させてみましょう。
下記を入力して実行してください。
(なお、#学習データ4を判定と書いてある行のコメントアウトを外せば、学習に使ったデータから画像を抜き出して判定できます)
from PIL import Image
import matplotlib.pyplot as plt
import numpy as np
im = Image.open("./3.bmp")
# グレースケールに変換
rgb = im.convert('RGB')
im2 = Image.new('L',(28,28))
for x in range(28):
for y in range(28):
r,g,b = rgb.getpixel((y,x))
gray= 255-int((r + g + b)/3)
#gray =int( X_test[4,x*28+y]*255) # 学習データ4を判定
im2.putpixel((x,y),(gray))
# イメージの表示
image_array = np.array(im2).T
plt.imshow(image_array)
# 予測
np.set_printoptions(suppress=True)
np.set_printoptions(precision=2)
target_array = image_array.reshape(1,784)
classes = model.predict(target_array, batch_size=1)
print(classes)
こんな結果が表示されました。
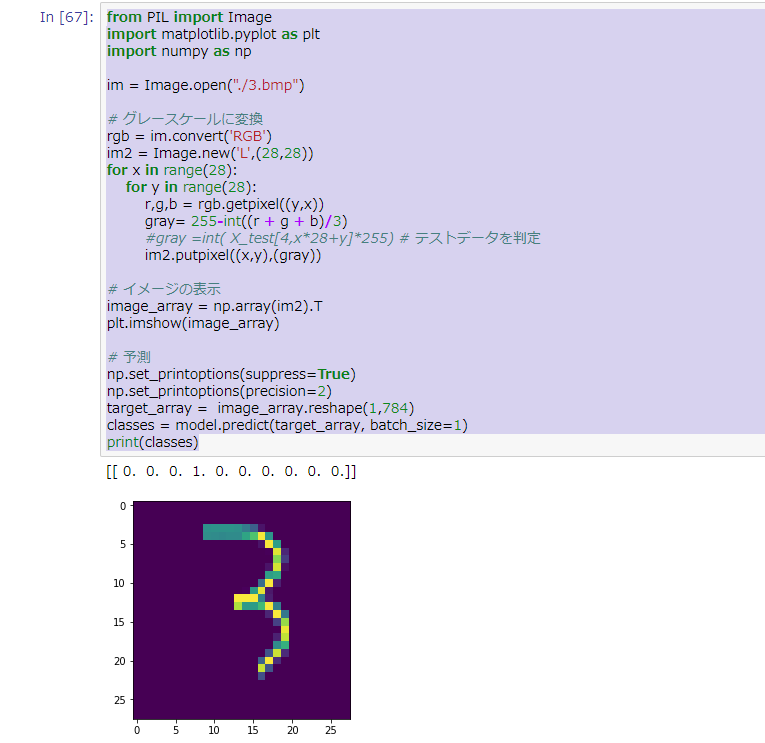
この結果は、左から、読み込ませた文字が0の確率、1の確率、2の確率…と並んでいます。
この結果によると100%の確率で、3とでました。
きちんと認識できていそうです。
ただし、他の画像だと完全に間違っていることもあります。
まだそんなに精度が高くないせいでしょうか。
このあたりのモデルの改善はまた別の機会にやってみましょう。
参考
Pythonで画像のピクセル操作
https://qiita.com/zaburo/items/0b9db87d0a52191b164b