Python独学ならTech-Joho TOP > django入門/ > Django 1.11 モデルの追加とマイグレーション
Djangoでモデルを追加する
こちらのDjango公式チュートリアル (バージョン1.11用)をやってみます。
https://docs.djangoproject.com/ja/1.11/intro/tutorial02/
そのままやっても意味がないので、モデル名を変えてみます。
初心者の方は、両方を見比べることで、どのようにモデルを作ればいいのかがわかると思います。
基本的に、こちらの記事の続きです。
設定
アプリ名は
“djangoTestApp”
だとします。
データベース名は
“django_test_app”
です。
データベース設定
mysqlにログインして
CREATE DATABASE django_test_app;
djangoTestApp2/settings.py
DATABASES = {
'default': {
#'ENGINE': 'django.db.backends.sqlite3',# もともとの設定
'ENGINE': 'django.db.backends.mysql',
#'NAME': os.path.join(BASE_DIR, 'db.sqlite3'), # もともとの設定
'NAME': 'django_test_app',
'USER': 'xxxx',
'PASSWORD': 'xxxx',
'HOST': '127.0.0.1'
}
}
上記のような書き方は、settings.pyの一部を表す。
例えば、上の例は76行目付近だった。
settings.pyを開いて、DATABASES等で検索して該当箇所まで移動して修正すること。
もしくは、設定ファイルを別に用意して使う
参考
https://docs.djangoproject.com/ja/1.11/ref/databases/#mysql-notes
djangoで使えるmysqlのアダプタはいくつかある
コンソール
> pip3 install mysqlclient
コンソールというのは、windows power shellや、コマンドプロンプトのこと
>の行の内容を入力する
ついでに、タイムゾーンと言語設定
djangoTestApp/settings.py
#LANGUAGE_CODE = 'en-us' LANGUAGE_CODE = 'ja-jp' #TIME_ZONE = 'UTC' TIME_ZONE = 'Asia/Tokyo'
タイムゾーンのリスト
https://en.wikipedia.org/wiki/List_of_tz_database_time_zones
マイグレーション実行の方法
コンソール
> python manage.py migrate Operations to perform: Apply all migrations: admin, auth, contenttypes, sessions Running migrations: Applying contenttypes.0001_initial... OK Applying auth.0001_initial... OK Applying admin.0001_initial... OK Applying admin.0002_logentry_remove_auto_add... OK Applying contenttypes.0002_remove_content_type_name... OK Applying auth.0002_alter_permission_name_max_length... OK Applying auth.0003_alter_user_email_max_length... OK Applying auth.0004_alter_user_username_opts... OK Applying auth.0005_alter_user_last_login_null... OK Applying auth.0006_require_contenttypes_0002... OK Applying auth.0007_alter_validators_add_error_messages... OK Applying auth.0008_alter_user_username_max_length... OK Applying sessions.0001_initial... OK
こんな感じの表示が出たら成功
モデル作成
もともとのチュートリアルは投票アプリケーションらしく、
Question(投票項目)とChoice(選択肢)という2つのモデルを定義する
同じ例ではつまらないので、はてなブックマークのようなソーシャルブックマークサービスを想定する
Article(記事)とBookmark(ブックマーク)
ブックマークにはstar(スター)をつける
アプリ作成からやりなおす
> python manage.py startapp bookmaker
bookmaker/urls.py
をつくり
djangoTestApp/urls.pyを修正する
仮のER図はこちらです。
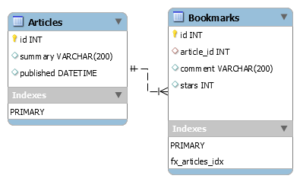
djangoのDB変更は3ステップ
- models.pyを変更
- python manage.py makemigrations でマイグレーションファイルを作成
- python manage.py migrate でマイグレーション実行
djangoTestApp/models.py
rom django.db import models
class Article(models.Model):
"""記事"""
summary = models.CharField(max_length=200)
published = models.DateTimeField('date published')
class Bookmark(models.Model):
"""ブックマーク"""
article = models.ForeignKey(Article, on_delete=models.CASCADE)
comment = models.CharField(max_length=200)
stars = models.IntegerField(default=0)
djangoTestApp/settings.py
INSTALLED_APPS = [ 'bookmarker.apps.BookmarkerConfig', 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', ]
モデルを確認して、マイグレーションファイルを作成する
> python manage.py makemigrations bookmarker
Migrations for 'bookmarker':
bookmarker\migrations\0001_initial.py
- Create model Article
- Create model Bookmark
0001というマイグレーションができた
できたマイグレーションの内容を確認
> python manage.py sqlmigrate bookmarker 0001 BEGIN; -- -- Create model Article -- CREATE TABLE `bookmarker_article` (`id` integer AUTO_INCREMENT NOT NULL PRIMARY KEY, `summary` varchar(200) NOT NULL, `published` datetime(6) NOT NULL); -- -- Create model Bookmark -- CREATE TABLE `bookmarker_bookmark` (`id` integer AUTO_INCREMENT NOT NULL PRIMARY KEY, `comment` varchar(200) NOT NULL, `stars` integer NOT NULL, `article_id` integer NOT NULL); ALTER TABLE `bookmarker_bookmark` ADD CONSTRAINT `bookmarker_bookmark_article_id_8c3fd859_fk_bookmarker_article_id` FOREIGN KEY (`article_id`) REFERENCES `bookmarker_article` (`id`); COMMIT;
CREATE TABLEのSQL文がふたつ
> python manage.py migrate
実行された
Shellでモデルの使い方の確認
シェル起動
> python manage.py shell
いろいろなメソッドを使ってみる
>>> from bookmarker.models import Article >>> Article.objects.all() >>> >>> from django.utils import timezone >>> a = Article(summary='This is the first article.', published=timezone.now()) >>> a.save() >>> a.id 1 >>> a.summary 'This is the first article.' >>> a.published datetime.datetime(2017, 10, 11, 4, 11, 25, 212888, tzinfo=) >>> Article.objects.all() ]>
モデル一覧を見てみたが、(Article.objects.all())中身がぜんぜんわからないので、表示設定をする
モデルに表示設定など追加
models.py
import datetime
from django.db import models
from django.utils import timezone
class Article(models.Model):
"""記事"""
summary = models.CharField(max_length=200)
published = models.DateTimeField('date published')
def __str__(self):
return self.summary
def was_published_recently(self):
return self.published >= timezone.now() - datetime.timedelta(days=1)
class Bookmark(models.Model):
"""ブックマーク"""
article = models.ForeignKey(Article, on_delete=models.CASCADE)
comment = models.CharField(max_length=200)
stars = models.IntegerField(default=0)
def __str__(self):
return self.comment
__str__というメソッドをそれぞれ追加した。
もう一回シェルを立ち上げて確認する
> python manage.py shell
モデルのいろいろな使い方を確認してみる
検索、取得、作成、削除など..
>>> from bookmarker.models import Article
>>> Article.objects.all()
]>
>>> Article.objects.filter(id=1)
]>
>>> Article.objects.filter(summary__startswith='This')
]>
>>> from django.utils import timezone
>>> current_year = timezone.now().year
>>> Article.objects.get(published__year=current_year)
>>> Article.objects.filter(id=2)
>>> Article.objects.get(id=2)
Traceback (most recent call last):
File "", line 1, in
略
self.model._meta.object_name
bookmarker.models.DoesNotExist: Article matching query does not exist.
>>> a1 = Article.objects.get(pk=1)
>>> a1.was_published_recently()
True
>>> a1.bookmark_set.all()
>>> a1.bookmark_set.create(comment='good!', stars=0)
>>> a1.bookmark_set.create(comment='bad', stars=10)
>>> b3 = a1.bookmark_set.create(comment='???', stars=2)
>>> b3.comment
'???'
>>> Bookmark.objects.filter(article__published__year=current_year)
, , ]>
>>> b3.delete()
(1, {'bookmarker.Bookmark': 1})
>>> Bookmark.objects.filter(article__published__year=current_year)
, ]>
管理画面
管理ユーザ作成
> python manage.py createsuperuser Username (leave blank to use 'xxxx'): admin Email address: admin@example.com Password: Password (again): This password is too short. It must contain at least 8 characters. This password is too common. Password: Password (again): Superuser created successfully.
最初passにしようとしたらtoo short too commonと怒られた。
passpassにしたら通った。これでいいのか?
アプリ起動
> python manage.py runserver
http://localhost:8000/admin
にアクセス
ログイン後
追加したモデルを管理対象にする
bookmaker/admin.py
from django.contrib import admin # Register your models here. from .models import Article, Bookmark admin.site.register(Article) admin.site.register(Bookmark)
もう一回アクセス
Articlesをクリック
This is the first article.をクリック
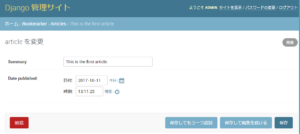
ちゃんとタイムゾーンで指定した通り、日本時間で表示されている
MySQLのDB内を直接のぞくと、UTCになっている
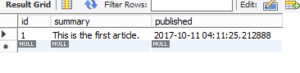
ちなみに、MySQL Workbenchを使っている
https://www.mysql.com/jp/products/workbench/
20日に変更して保存
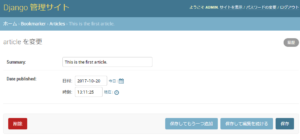
これでチュートリアル2は終わり